Handling Streaming Data in LLM Software Architectures
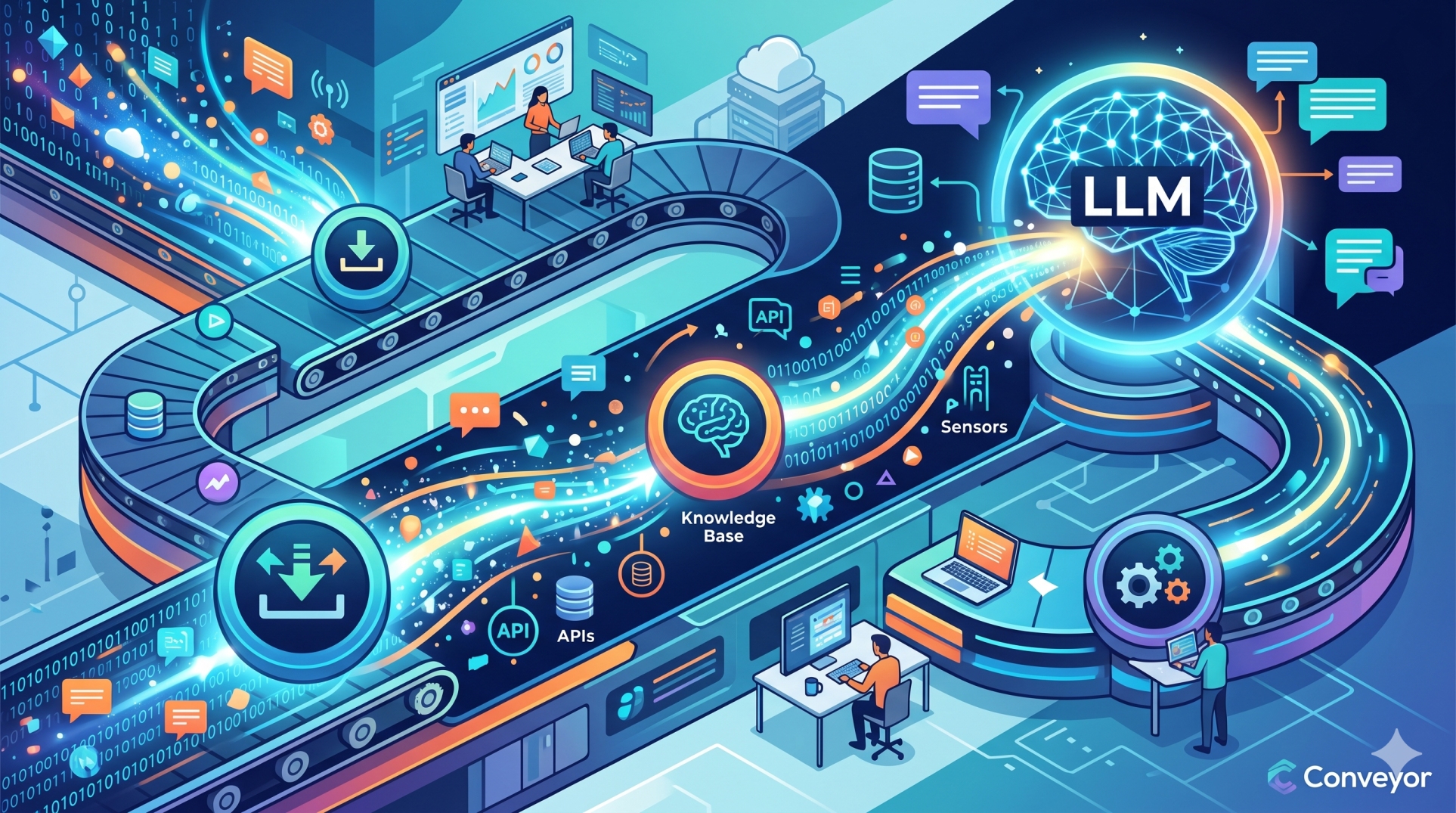
Handling Streaming Data in LLM Software Architectures
As Large Language Model (LLM) applications become increasingly interactive and real-time, handling streaming data has become a critical architectural requirement. Modern AI systems must process continuous data flows from user interactions, APIs, IoT devices, enterprise systems, and live events without sacrificing performance or reliability. Efficient streaming data architectures enable responsive AI experiences, scalable inference pipelines, and continuous contextual awareness across LLM-powered platforms.
Step 1: Understanding Streaming Data in LLM Systems 🌊
• Streaming data refers to continuously generated information processed in real time ⚡
• LLM applications consume streams from chats, sensors, APIs, and business systems 🔗
• Real-time processing enables instant responses and dynamic decision-making 🧠
• Streaming architectures support adaptive and context-aware AI workflows 🤖
• Continuous data handling improves responsiveness and operational efficiency 📈
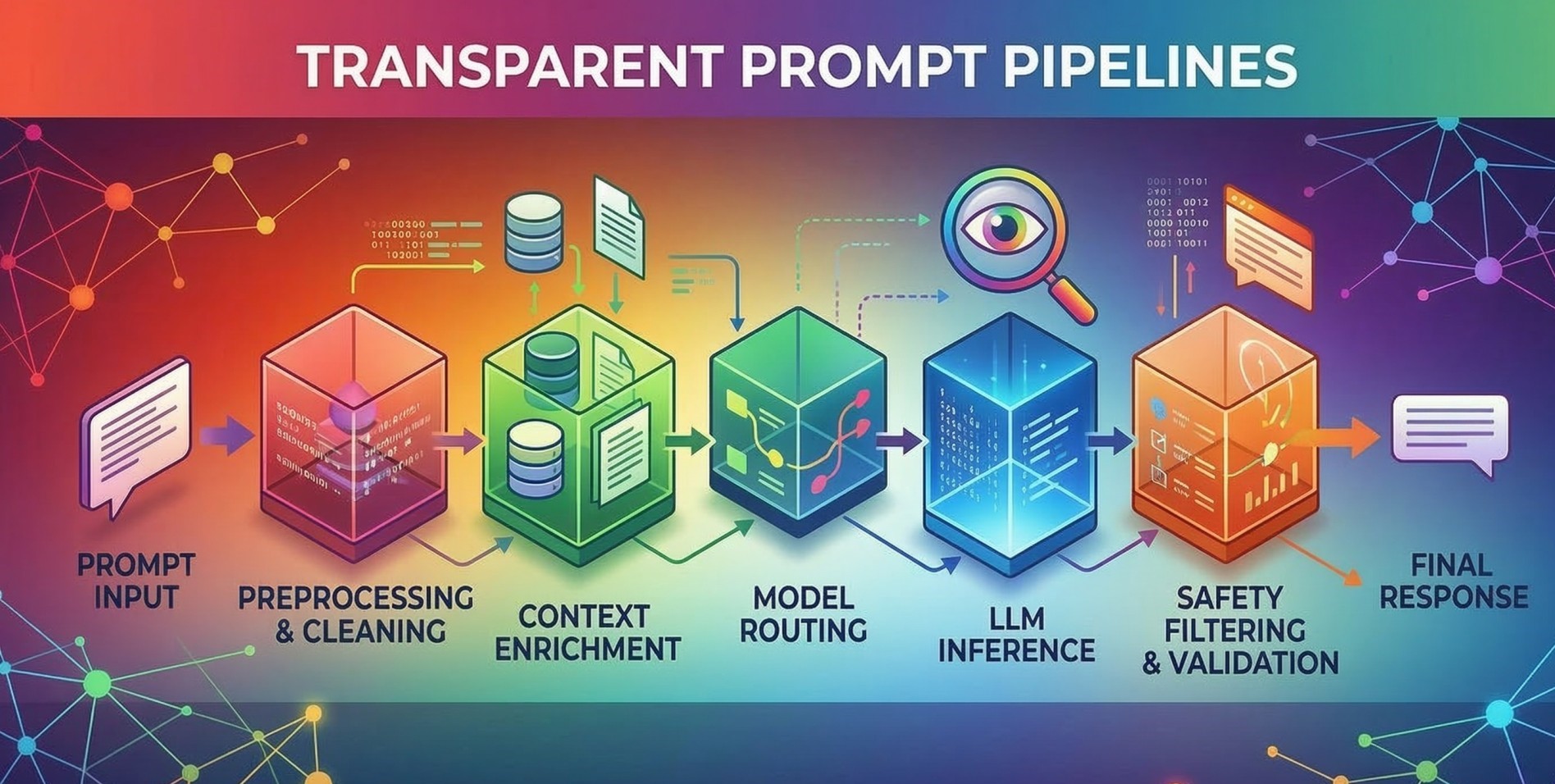
Step 2: Designing Real-Time Data Pipelines 🏗️
• Build pipelines capable of ingesting high-volume live data streams 🚀
• Use event-driven architectures for scalable data processing 🔄
• Ensure low-latency communication between data producers and consumers ⚡
• Separate ingestion, processing, and storage layers for flexibility 🧩
• Design pipelines that support horizontal scalability across workloads 🌐
Step 3: Managing Data Ingestion Efficiently 📥
• Collect streaming data from multiple internal and external sources 🔗
• Validate and filter incoming data before processing 🛡️
• Normalize data formats for consistency across systems 📊
• Prevent bottlenecks during high-throughput ingestion scenarios 🚦
• Ensure reliable message delivery and fault tolerance ✅
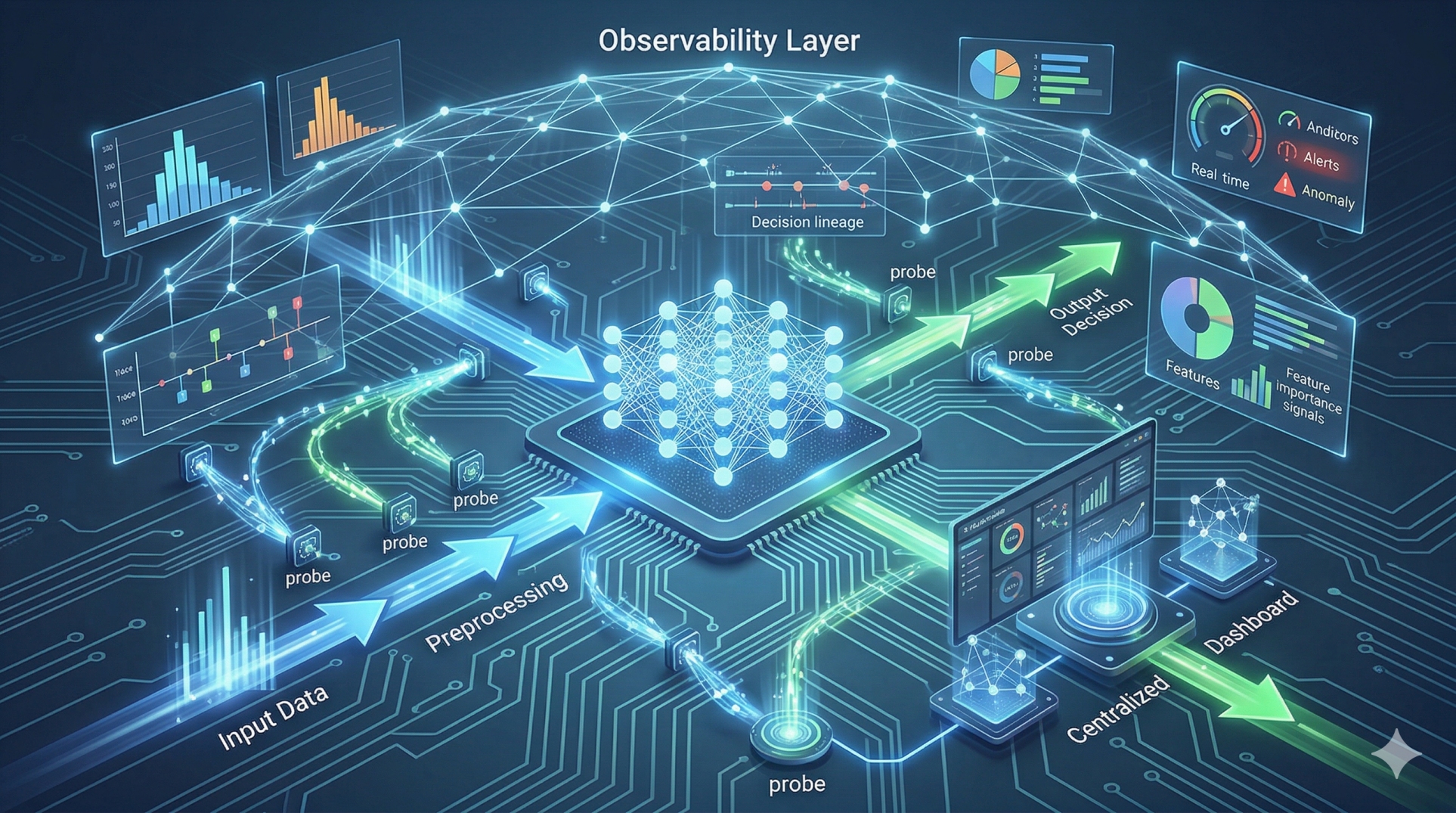
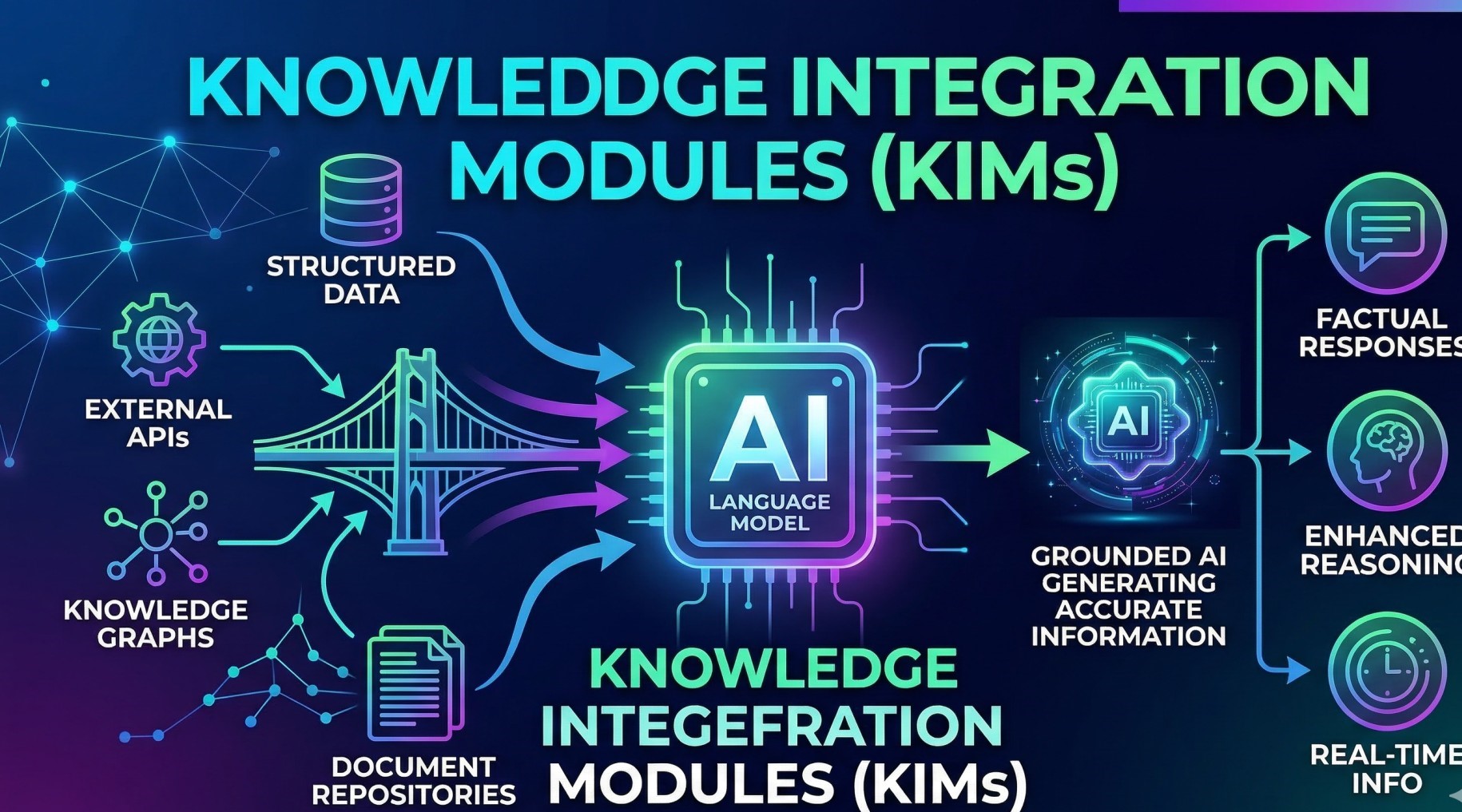
Step 4: Real-Time Context Enrichment 🧠
• Enrich streaming data with metadata and historical context 📂
• Combine live events with stored enterprise knowledge 🔍
• Maintain contextual continuity across user interactions 💬
• Support memory-aware AI responses using dynamic context updates 🔄
• Improve LLM relevance through continuous contextual enhancement 🎯
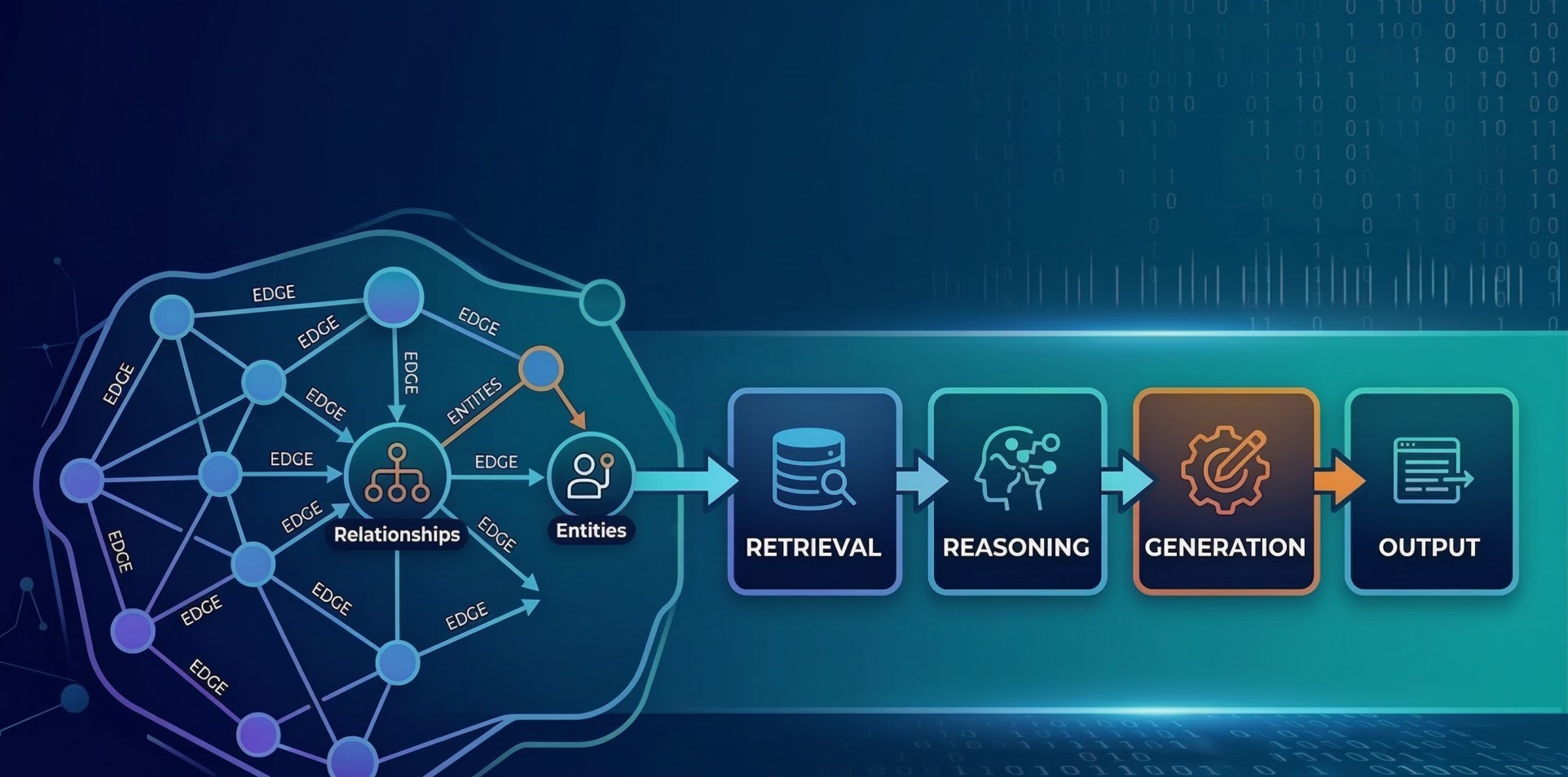
Step 5: Stream Processing and Event Handling ⚙️
• Process events as they occur without batch-processing delays ⚡
• Trigger workflows based on real-time conditions and events 🚨
• Detect anomalies, trends, or operational changes instantly 📈
• Support asynchronous processing for scalability 🔄
• Enable intelligent routing of streaming workloads 🧭
Step 6: Scaling LLM Inference for Streaming Workloads 🚀
• Optimize inference pipelines for continuous real-time requests ⚡
• Distribute workloads across scalable compute infrastructure 🌐
• Reduce latency through efficient request orchestration 🧩
• Support concurrent user interactions without performance degradation 👥
• Dynamically allocate resources based on streaming demand 📊
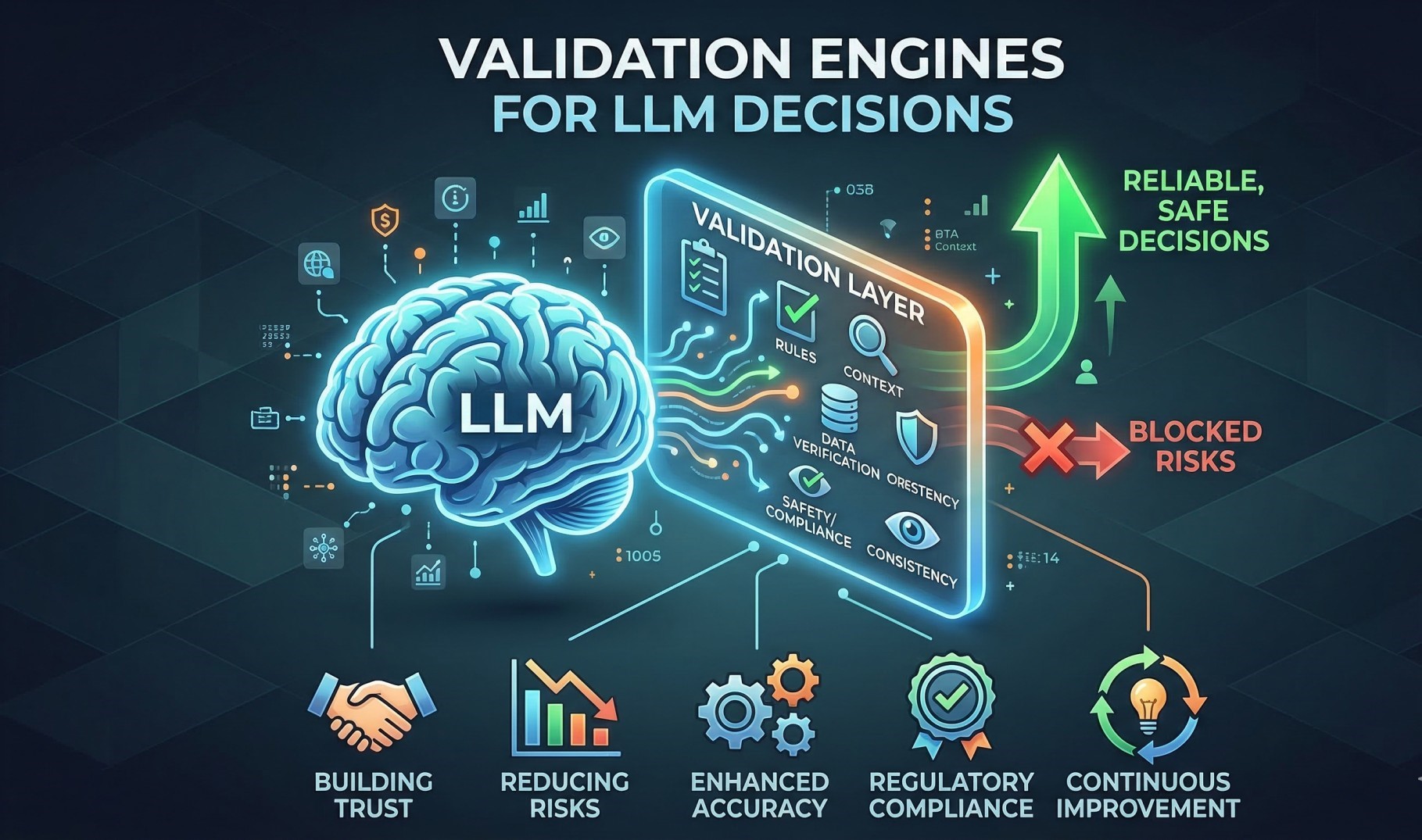
Step 7: Ensuring Reliability and Fault Tolerance 🛡️
• Implement failover mechanisms for uninterrupted operations 🔄
• Buffer streaming data during temporary outages 📥
• Ensure message persistence and recovery capabilities 💾
• Monitor pipeline health continuously for early issue detection 👁️
• Maintain system resilience under peak traffic conditions ⚙️
Step 8: Key Streaming Architecture Priorities 📌
• Low-latency processing for real-time responsiveness ⚡
• Scalable infrastructure for high-volume data streams 🌍
• Reliable event handling and fault tolerance 🛡️
• Continuous context management for intelligent AI outputs 🧠
Step 9: Security and Data Governance 🔐
• Secure streaming channels using encryption and authentication 🔒
• Enforce access controls across data pipelines 🛡️
• Monitor sensitive information flowing through AI systems 👁️
• Maintain compliance with privacy and regulatory standards 📜
• Audit streaming activity for transparency and accountability 📋
Step 10: Building Future-Ready Streaming Architectures 🌟
• Design modular systems that adapt to evolving AI workloads 🧩
• Support integration with emerging real-time technologies 🔗
• Enable continuous optimization through monitoring and analytics 📈
• Prepare infrastructure for growing user and data demands 🚀
• Future-proof architectures for next-generation AI applications 🤖
Conclusion
Handling streaming data in LLM software architectures is essential for delivering responsive, scalable, and intelligent AI systems. By combining real-time processing, scalable infrastructure, and continuous context management, organizations can build AI platforms capable of adapting to dynamic operational environments. Well-designed streaming architectures not only improve current system performance but also establish the foundation for future innovation in real-time AI applications.
See more blogs
You can all the articles below