Transparent Prompt Processing in Modular LLM Platforms
Transparent Prompt Processing in Modular LLM Platforms
As Large Language Model platforms become more complex and widely deployed, transparency in how prompts are processed is becoming increasingly important. Modular LLM platforms break prompt handling into distinct components such as preprocessing, routing, context enrichment, and response generation. Transparent prompt processing ensures that each stage of this pipeline is observable, interpretable, and controllable, enabling organizations to build reliable, auditable, and trustworthy AI systems.
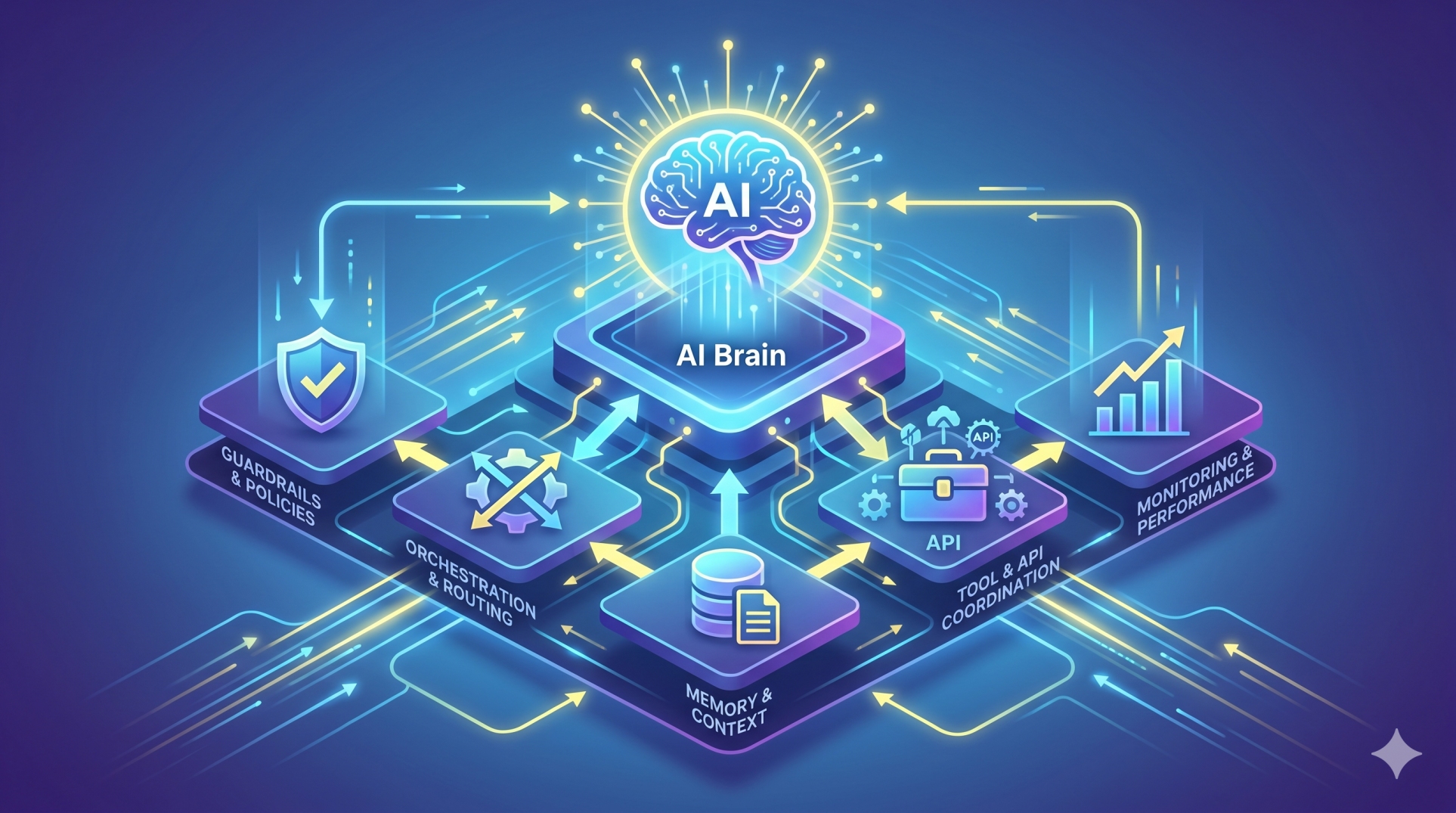
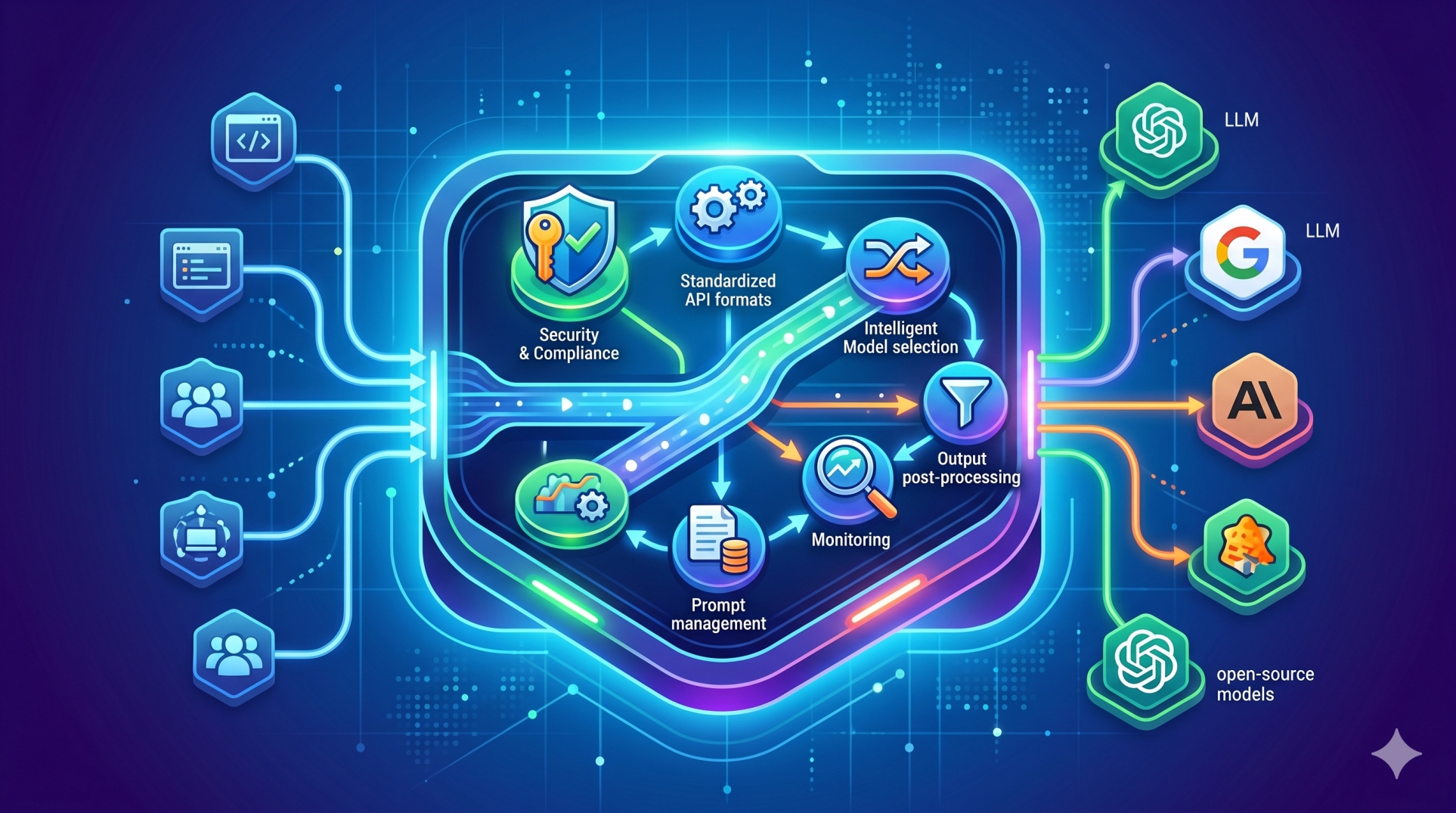
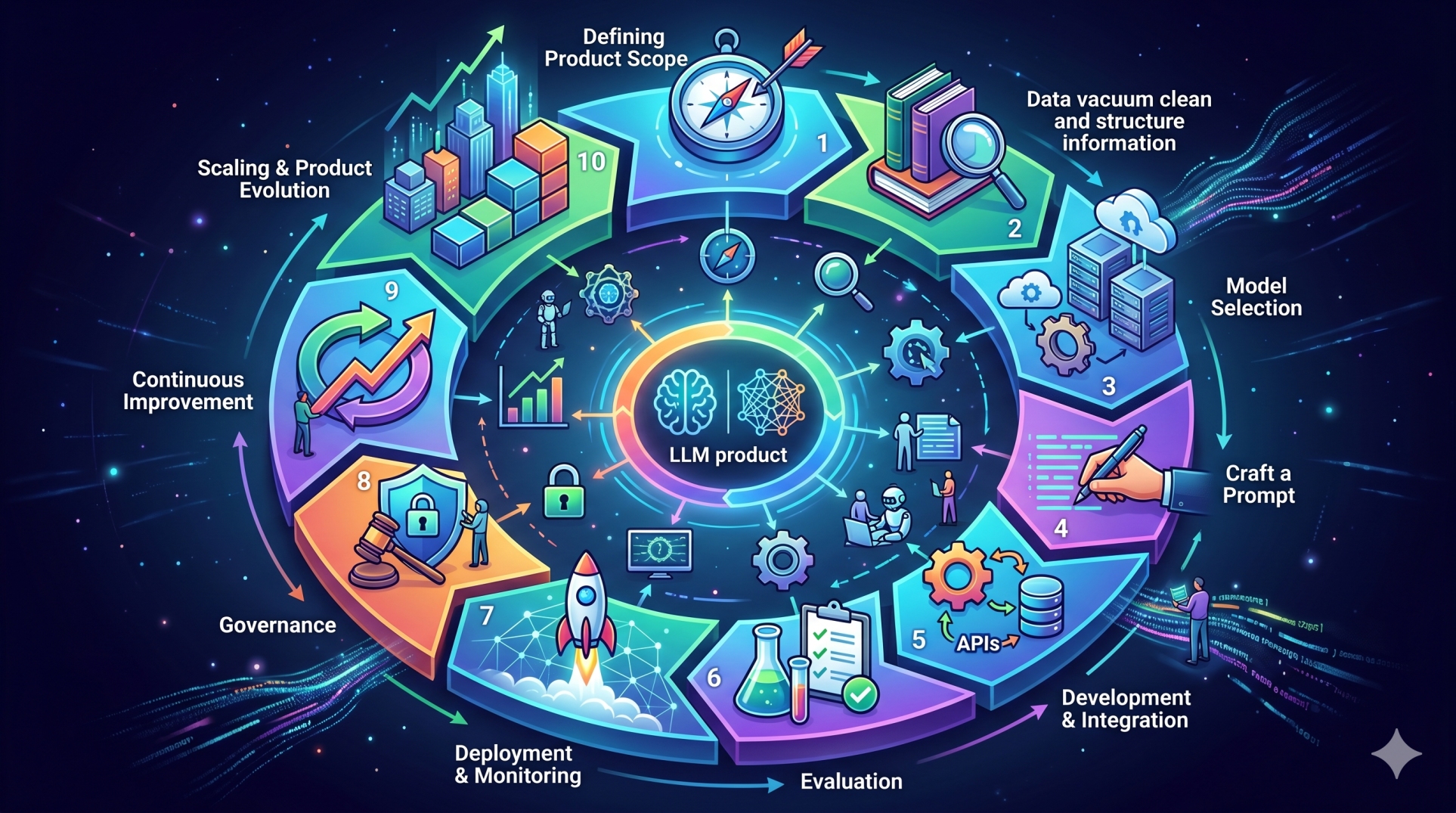
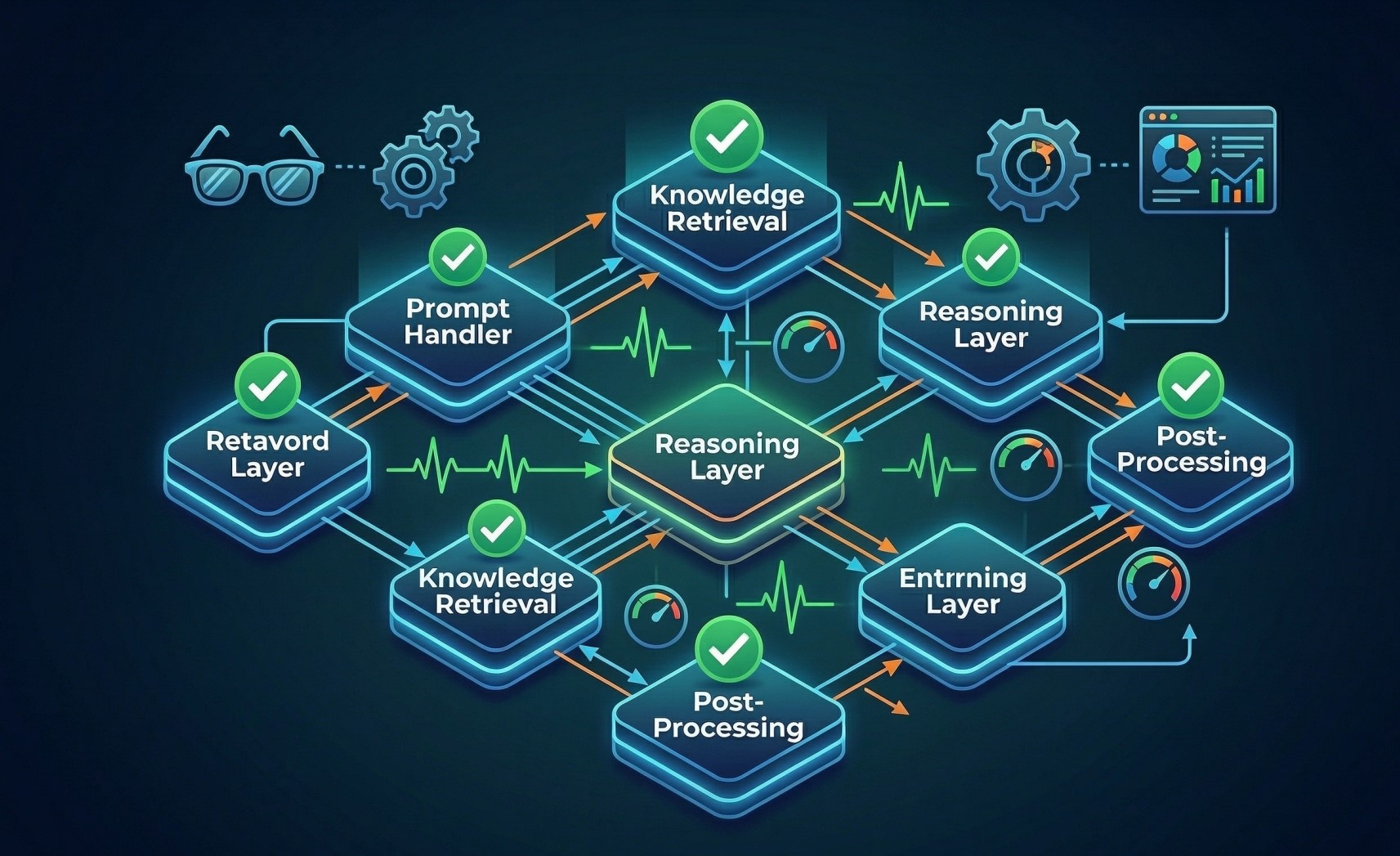
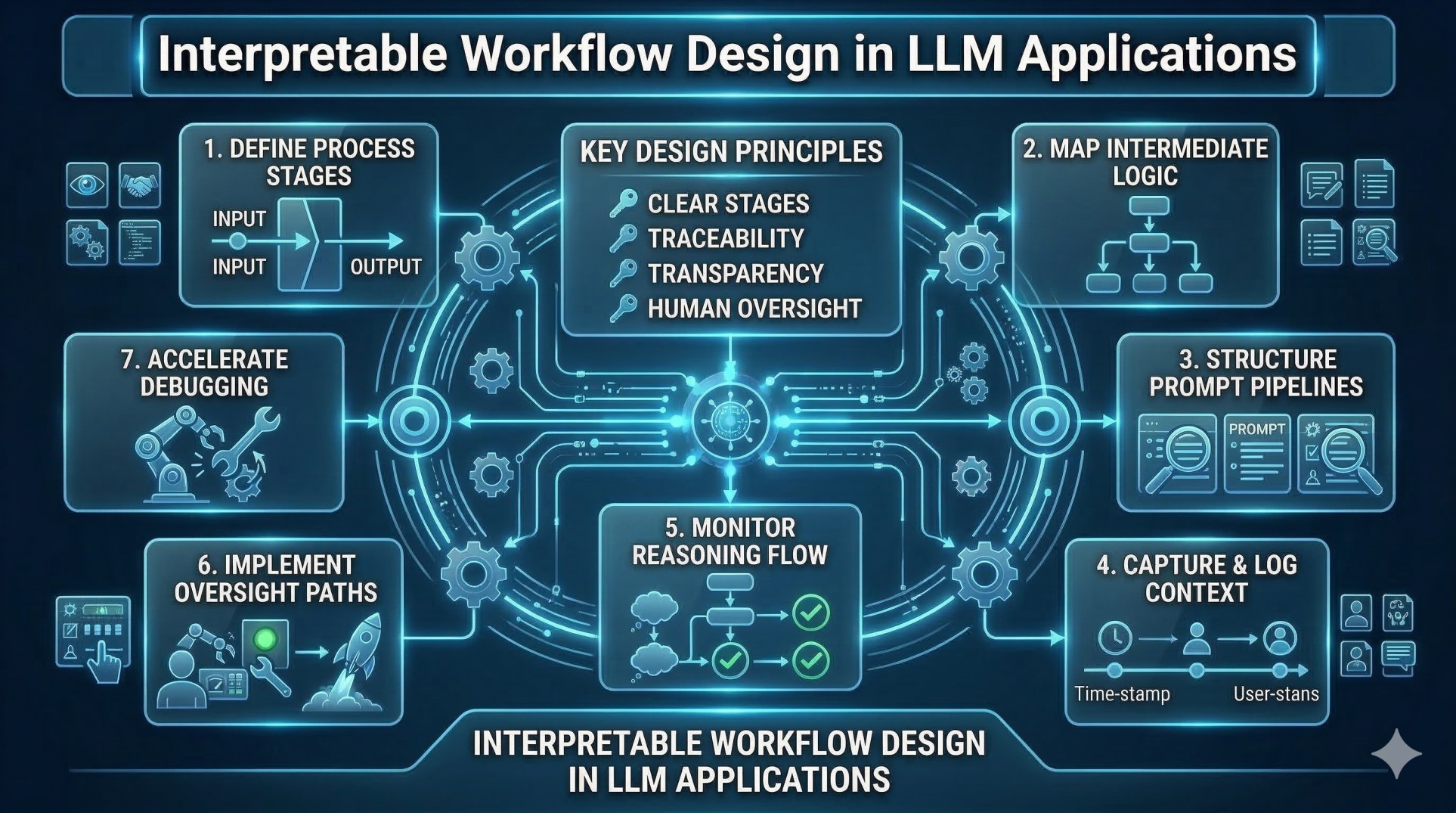
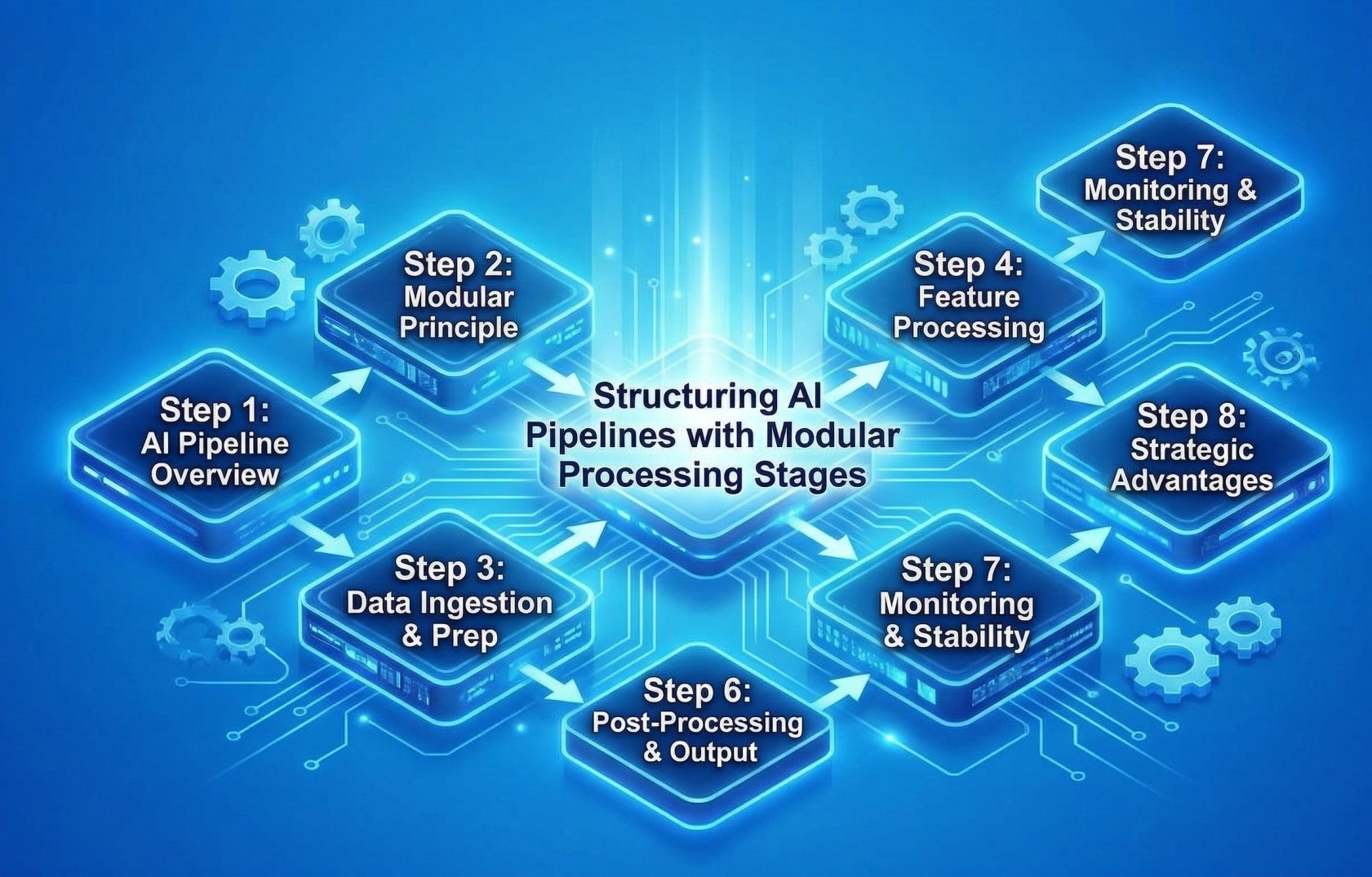
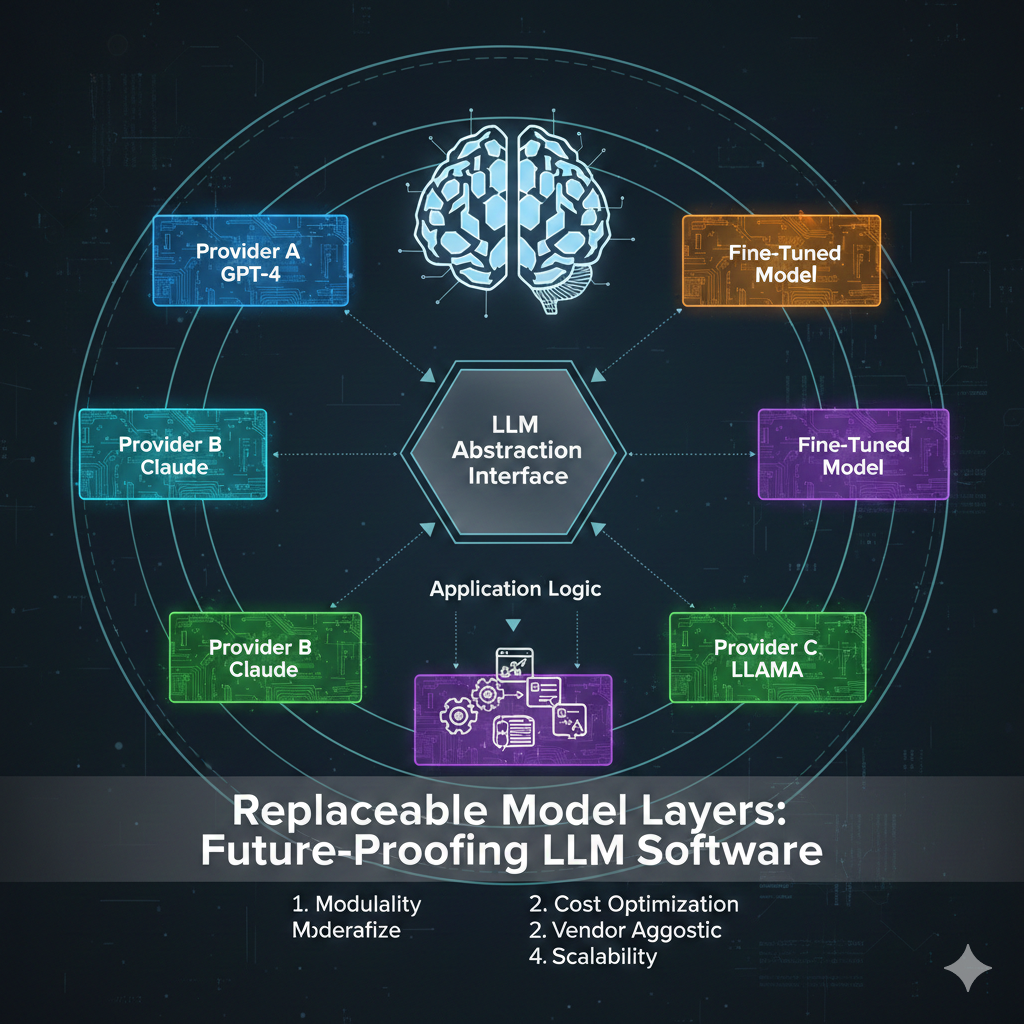
1. Understanding Modular LLM Platform Architecture 🧩
• Modular platforms divide LLM operations into separate functional components ⚙️
• Each module handles a specific responsibility within the prompt lifecycle 🔄
• Components may include preprocessing, context retrieval, model inference, and response validation 🧠
• Modular design improves scalability, maintainability, and flexibility 📈
• Clear module boundaries enable better system transparency 🔍
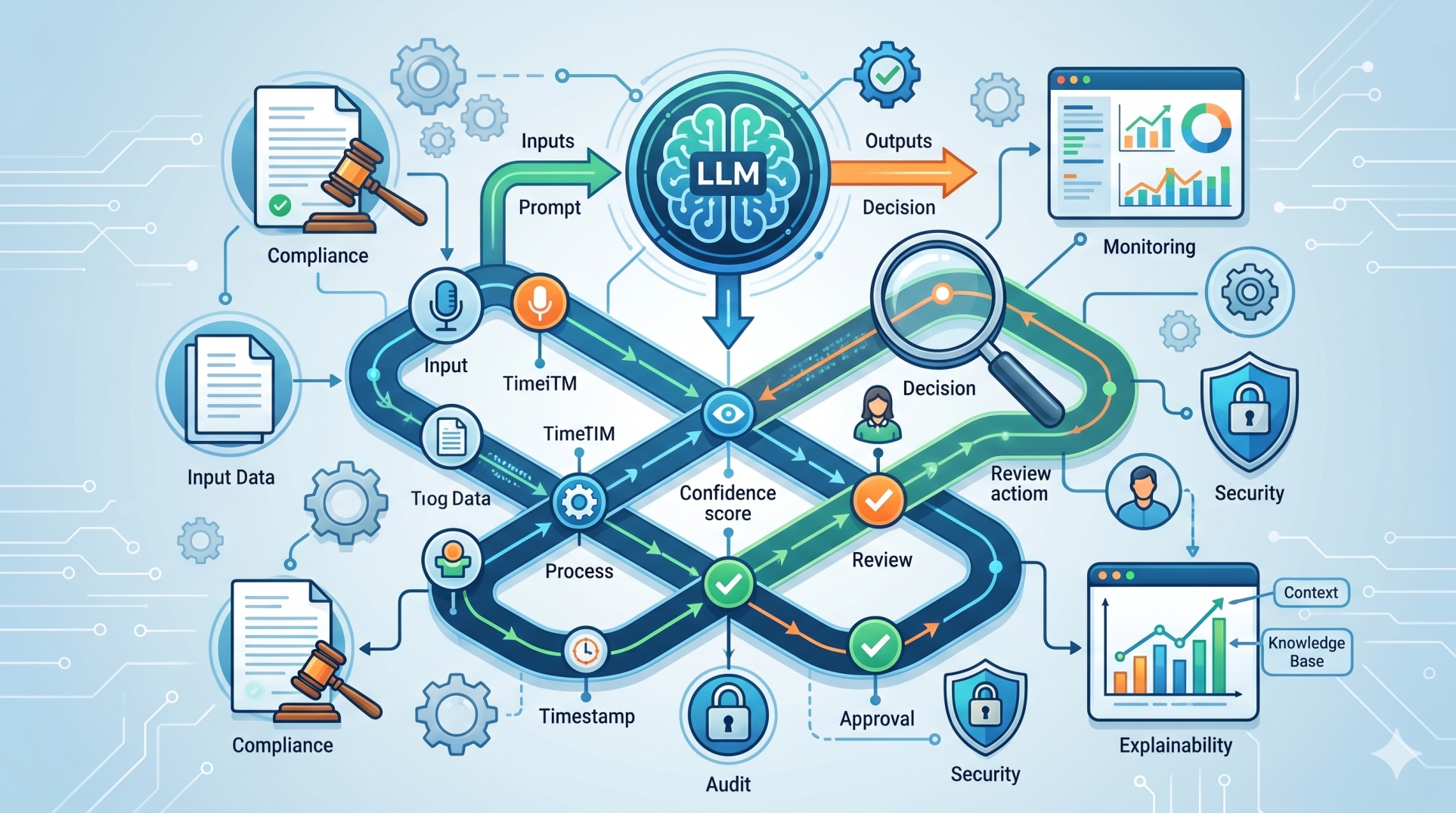
2. What Transparent Prompt Processing Means 🔎
• Provides visibility into how prompts are interpreted and transformed 👀
• Tracks how inputs move through different processing stages 🔄
• Exposes intermediate outputs generated by system components 🧾
• Enables developers to understand how final responses are produced 🧠
• Supports debugging, optimization, and accountability 🛠️
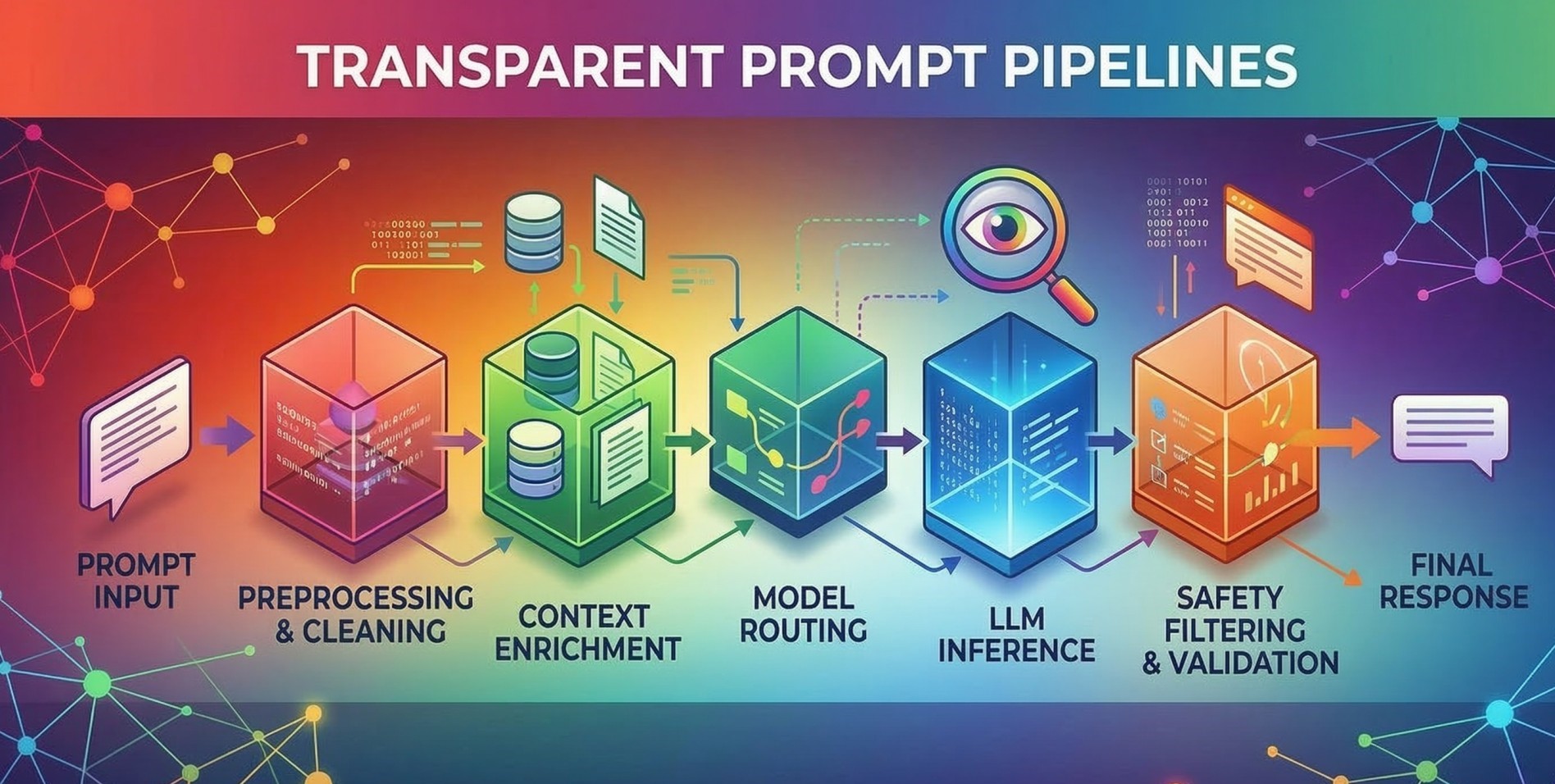
3. Prompt Preprocessing and Normalization ⚙️
• Cleans and standardizes incoming prompts before model interaction 🧹
• Handles formatting adjustments, token management, and language normalization 📝
• Filters harmful or malformed input before it reaches the model 🚫
• Ensures consistent prompt structure across applications 🔁
• Improves reliability and predictability of model responses 📊
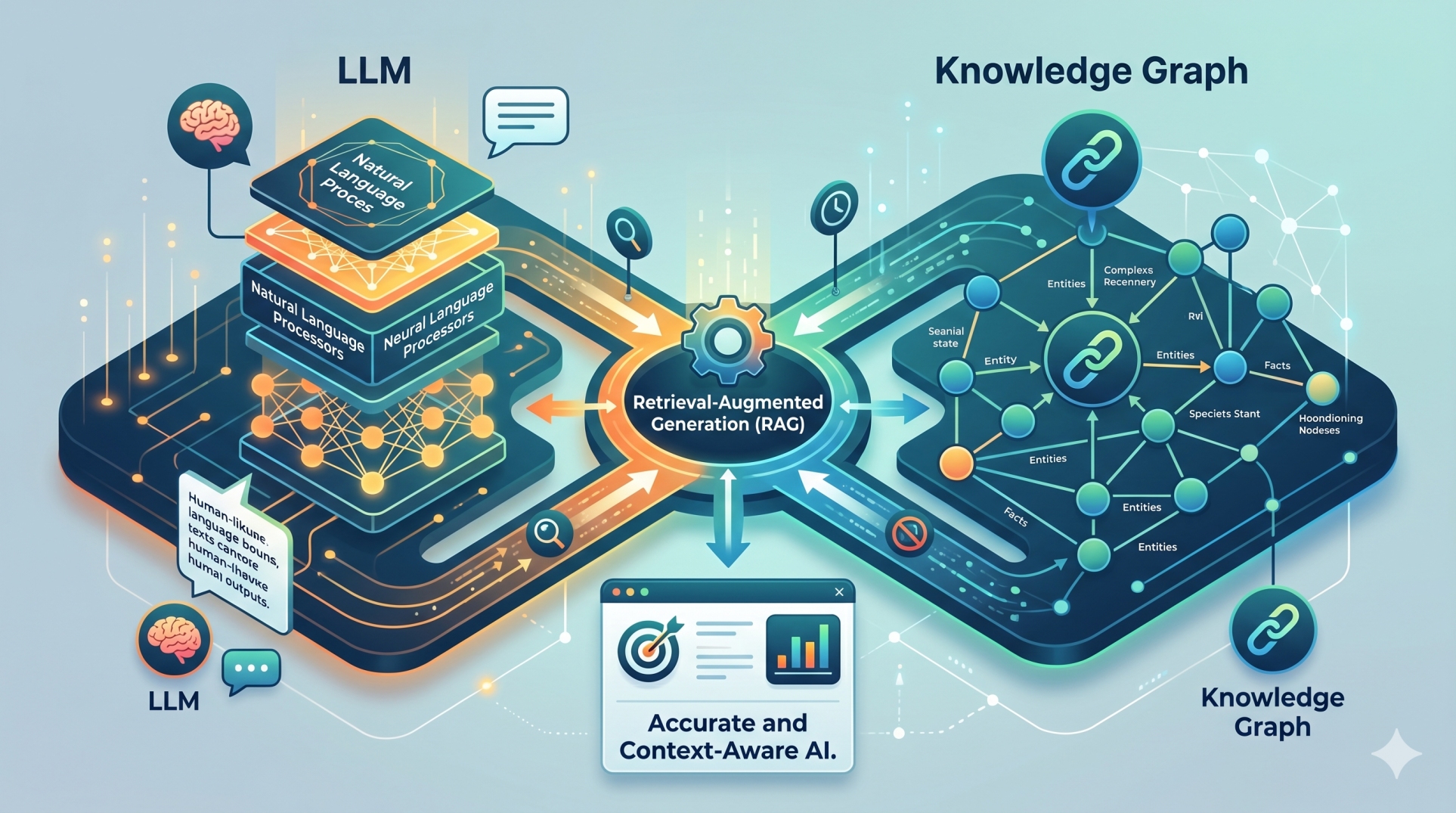
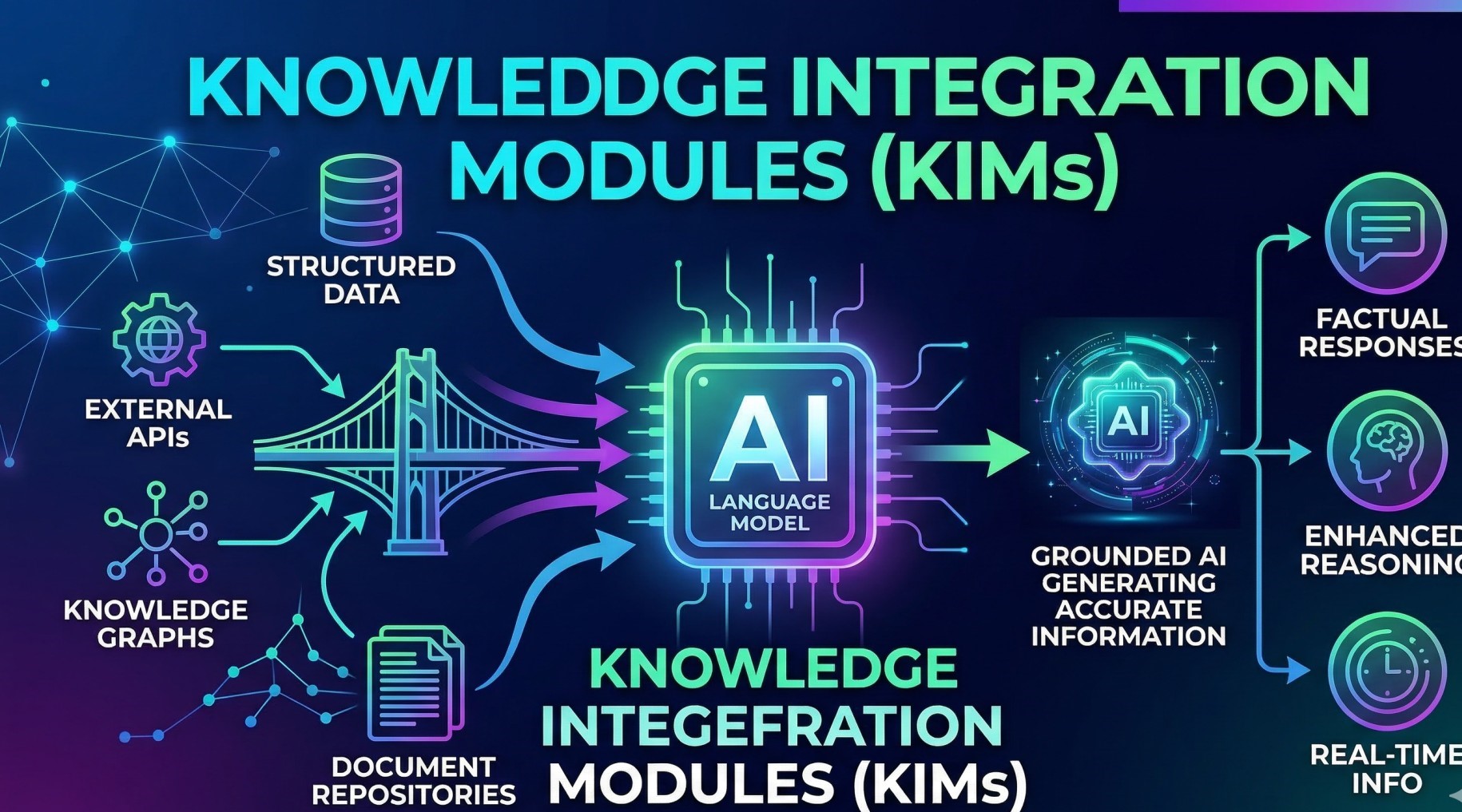
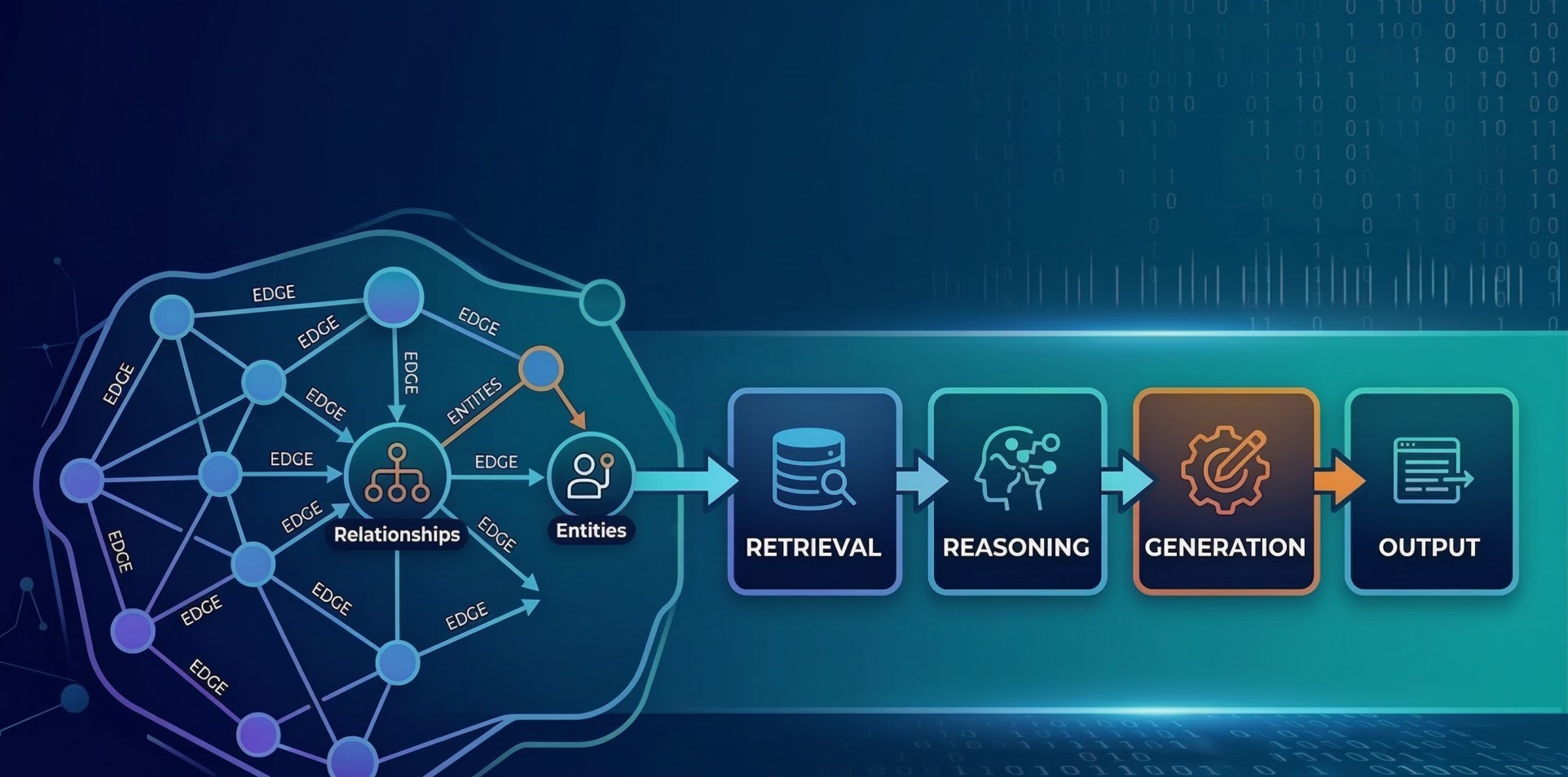
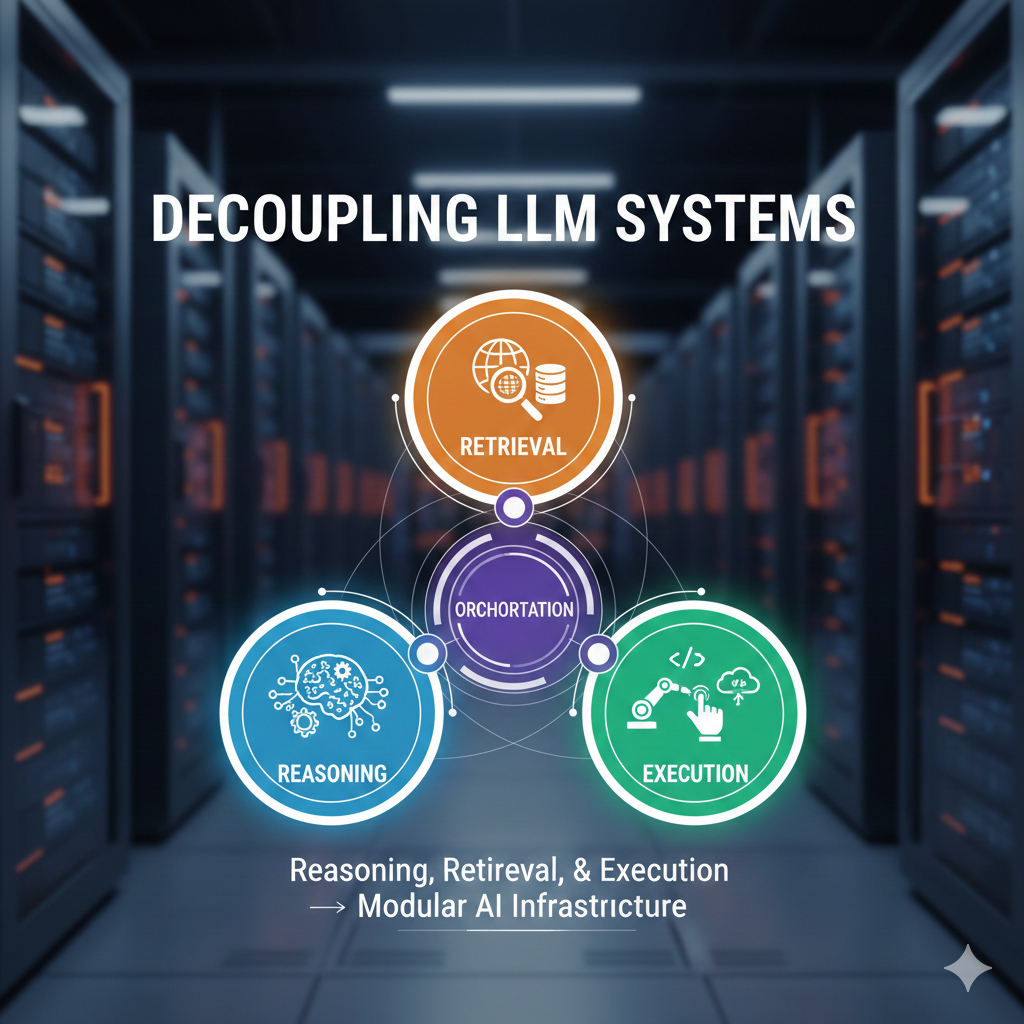
4. Context Injection and Knowledge Integration 📚
• Adds relevant context from databases, knowledge bases, or documents 📂
• Expands prompts with retrieved information for better accuracy 🔗
• Supports retrieval-augmented generation workflows 🤖
• Ensures that responses are grounded in external knowledge sources 📖
• Improves factual relevance and contextual understanding 🎯
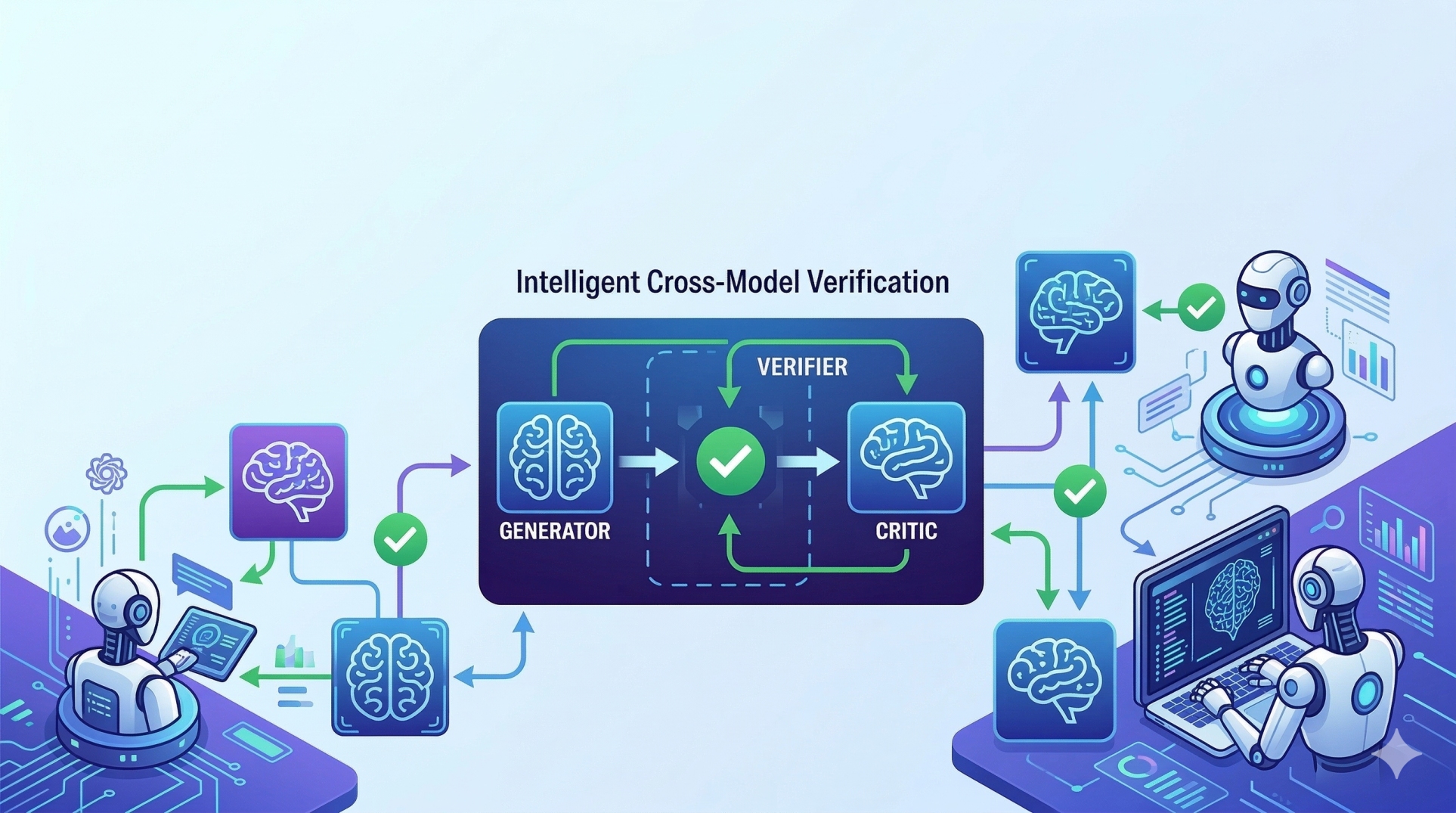
5. Prompt Routing and Model Selection 🔀
• Determines which model or system component should process a prompt 🤖
• Routes requests based on complexity, domain, or task requirements 📊
• Supports specialized models for different functions ⚙️
• Improves efficiency by matching tasks to appropriate resources ⚡
• Enables dynamic orchestration across multiple models 🔄
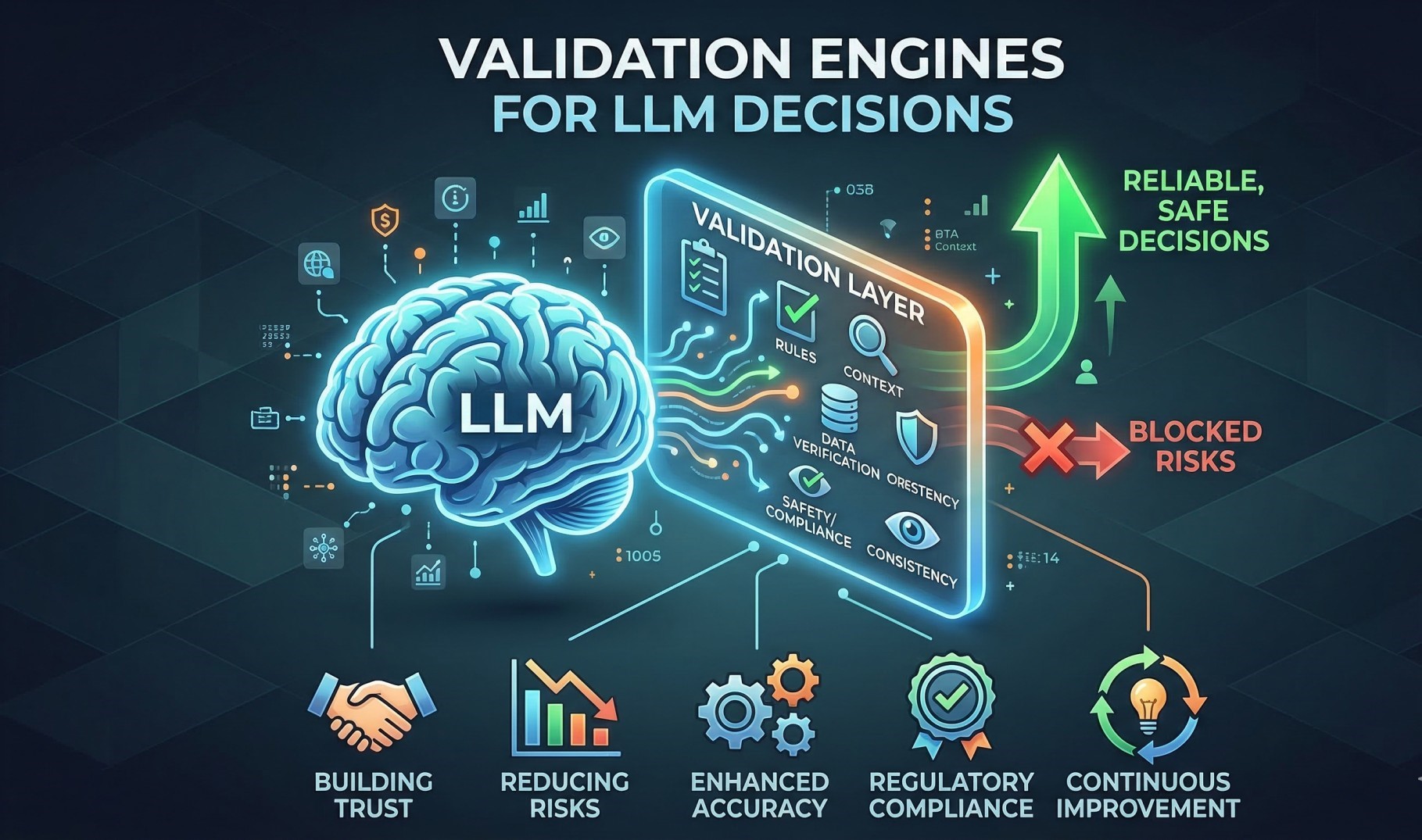
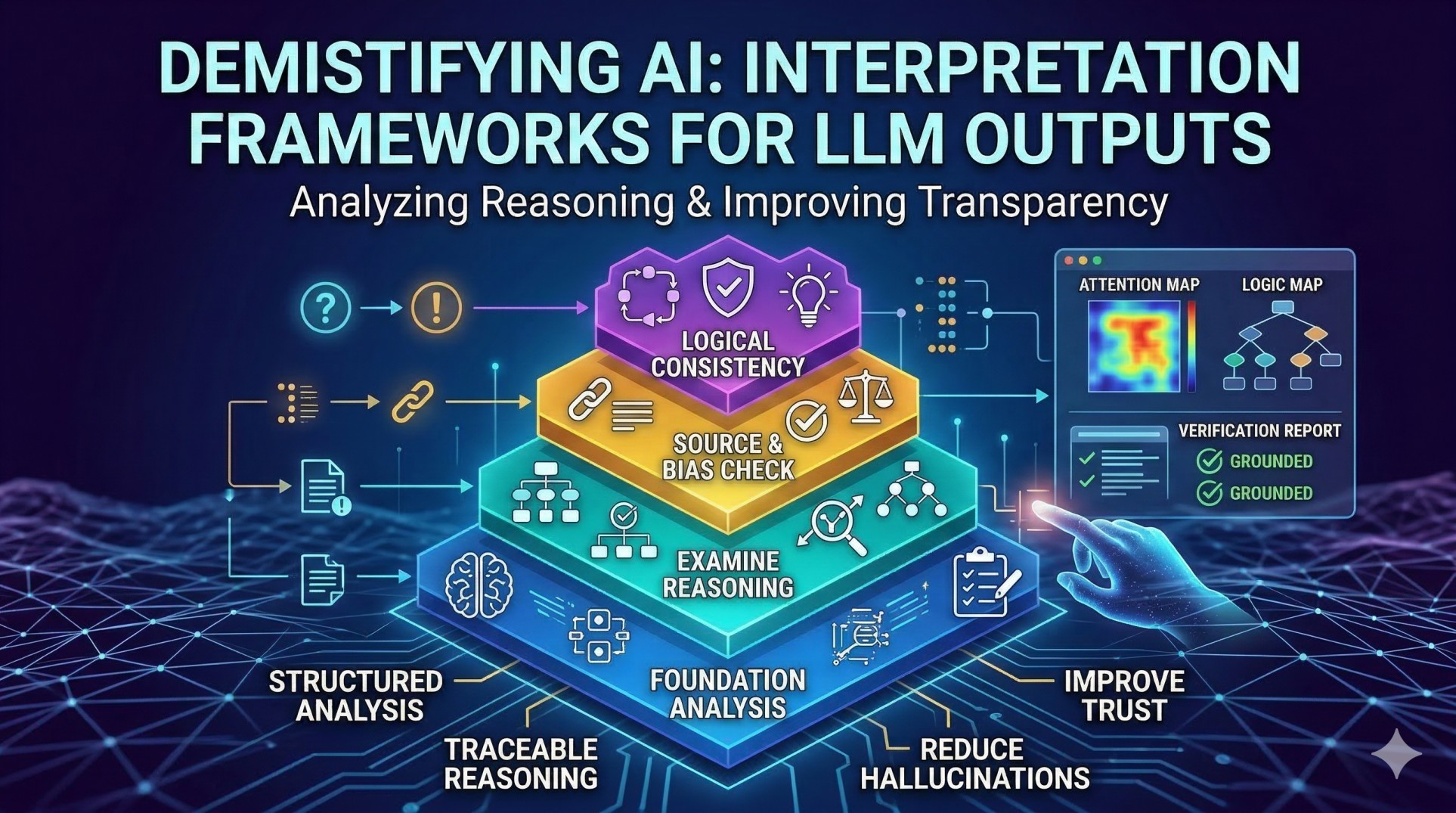
6. Response Validation and Safety Filtering 🛡️
• Reviews generated outputs before delivering them to users 🔍
• Detects hallucinations, unsafe content, or policy violations ⚠️
• Applies rule-based and model-based validation layers 🧠
• Enforces compliance with organizational guidelines 📜
• Maintains quality and safety standards ✔️
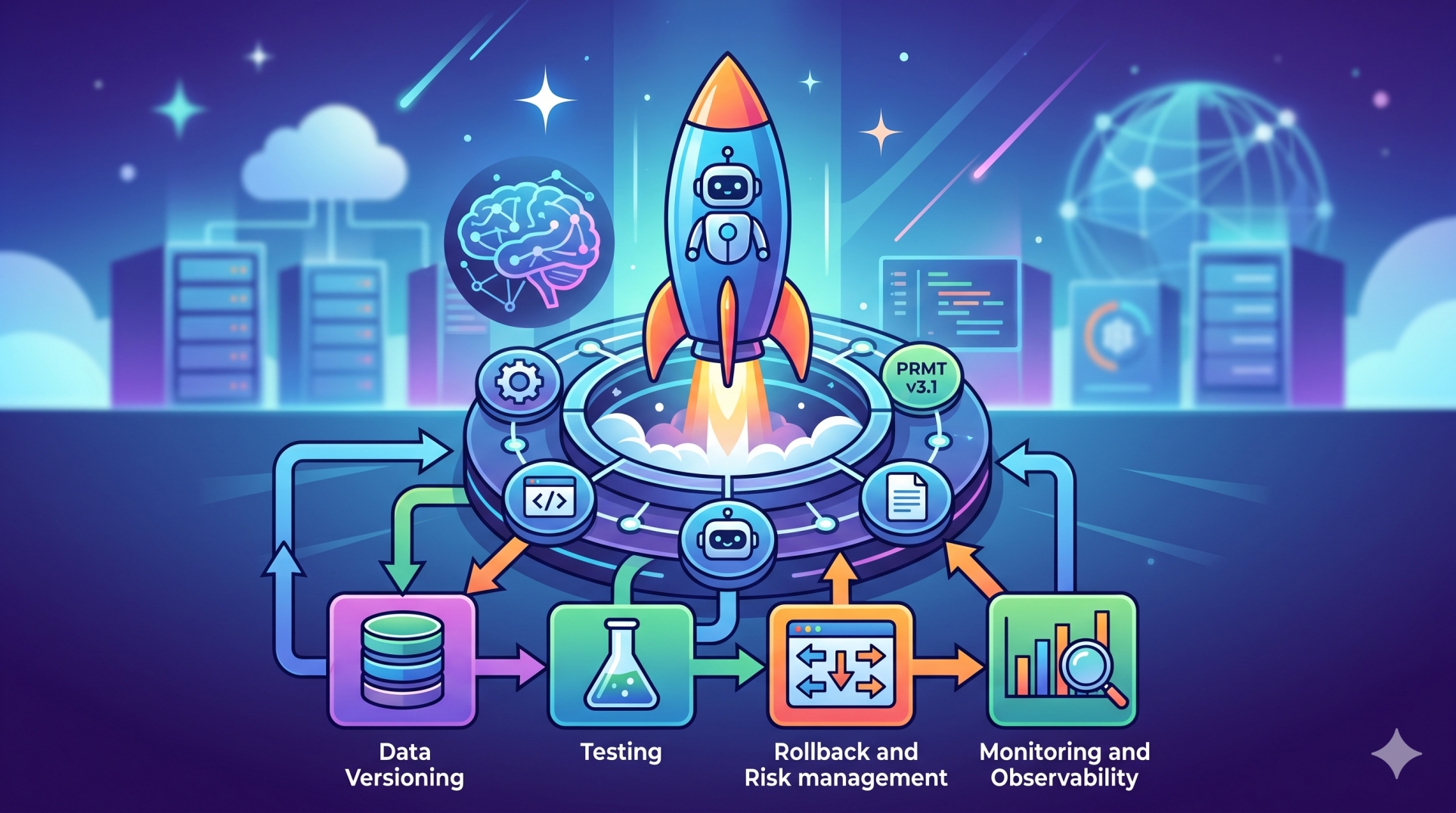
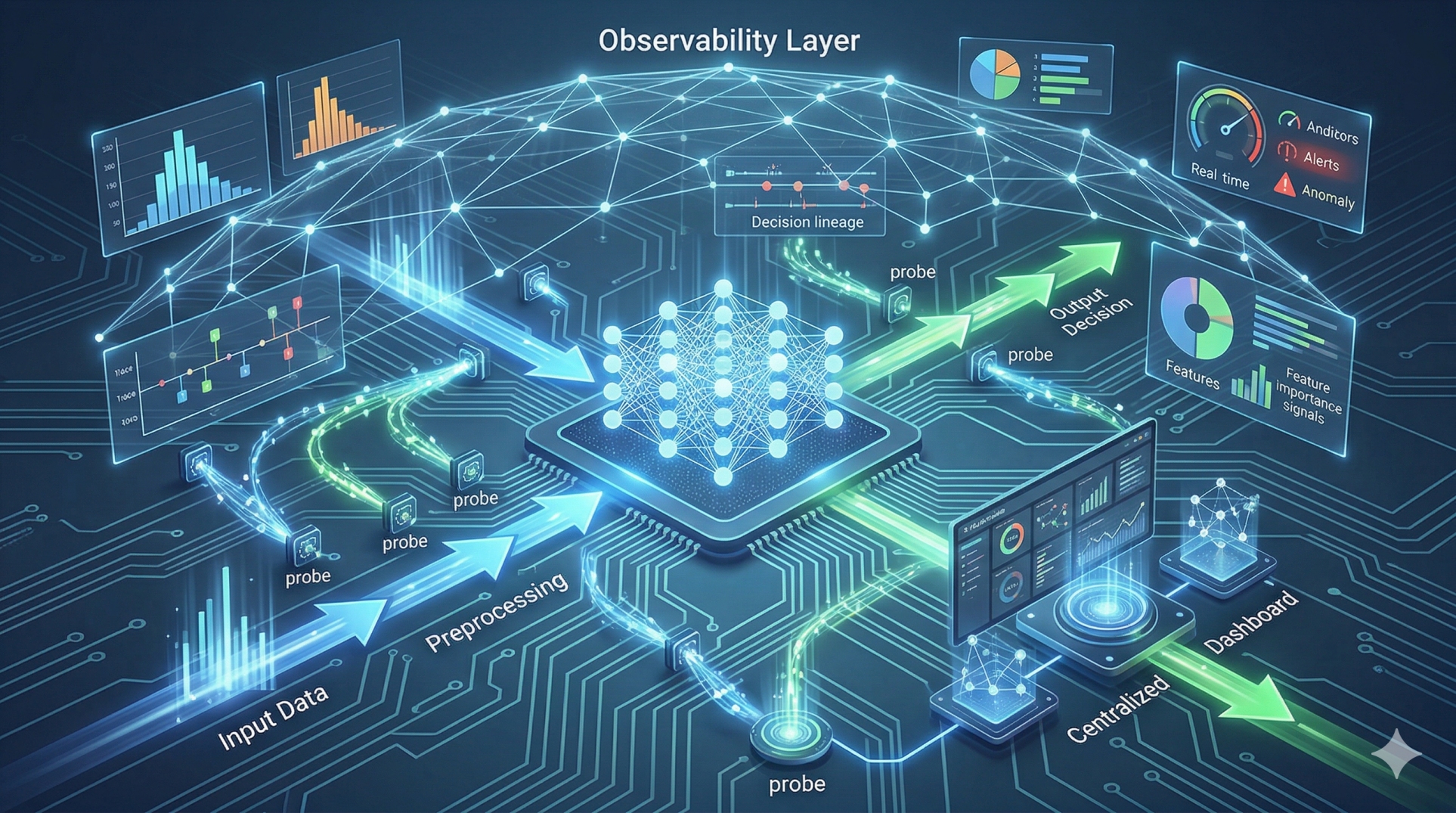
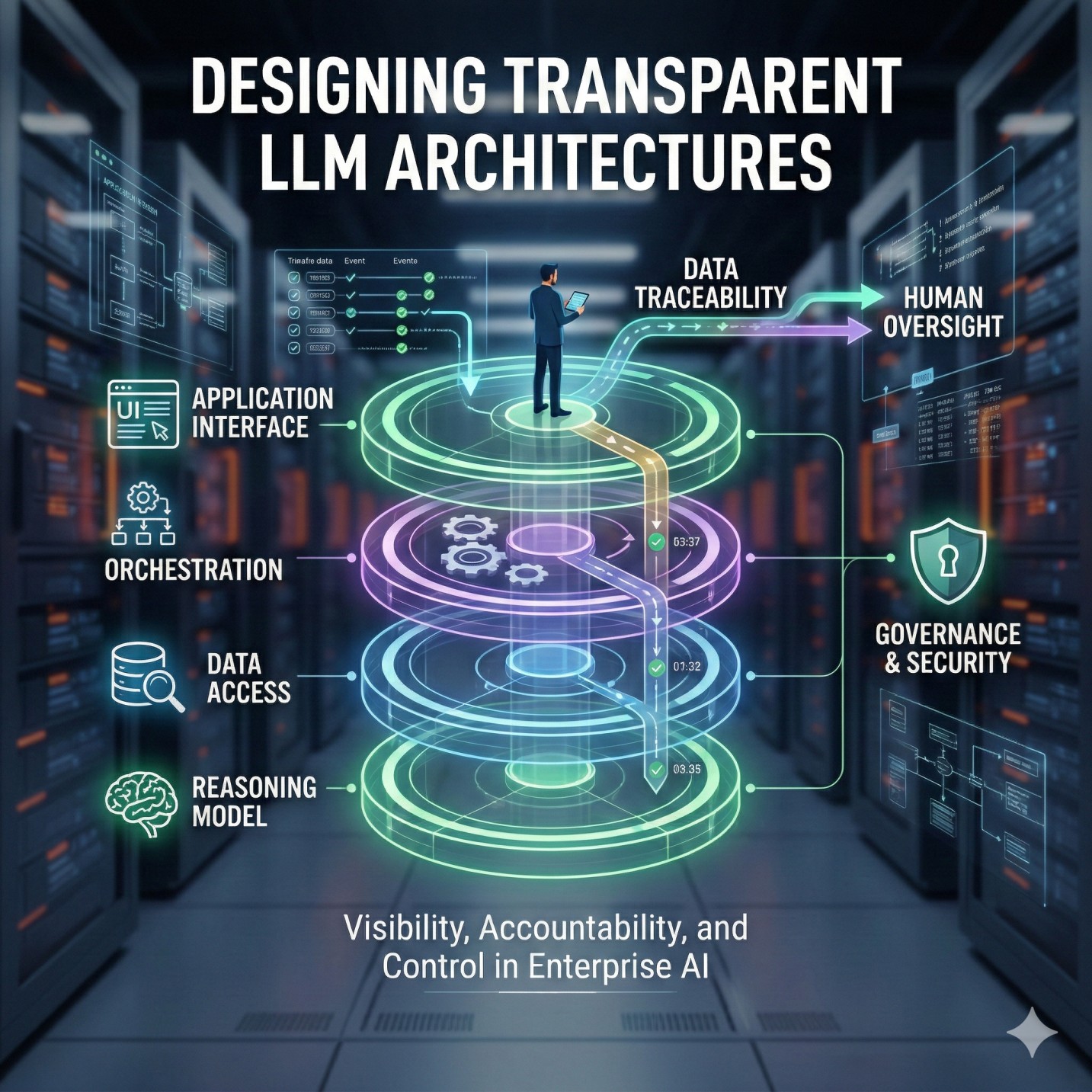
7. Observability and Traceability in Prompt Pipelines 📊
• Logs every step of the prompt processing workflow 📝
• Captures metadata, system decisions, and intermediate outputs 📂
• Enables reproducibility of model behavior for debugging 🔄
• Supports performance monitoring and evaluation pipelines 📈
• Improves accountability in production AI systems 🏢
8. Strategic Value of Transparent Prompt Processing 🚀
• Builds trust in AI systems through explainable workflows 🤝
• Enables governance, auditing, and responsible AI deployment 🏛️
• Supports faster debugging and system optimization ⚡
Conclusion
Transparent prompt processing is a critical capability for modern modular LLM platforms. By making each stage of prompt handling observable and interpretable, organizations gain greater control over AI behavior, improve system reliability, and ensure responsible deployment. As LLM applications continue to scale across industries, transparency in prompt pipelines will play a key role in building trustworthy and maintainable AI infrastructure.
See more blogs
You can all the articles below