Unsupervised Clustering: Finding Hidden Patterns in Data
🧠 Unsupervised Clustering: Finding Hidden Patterns in Data
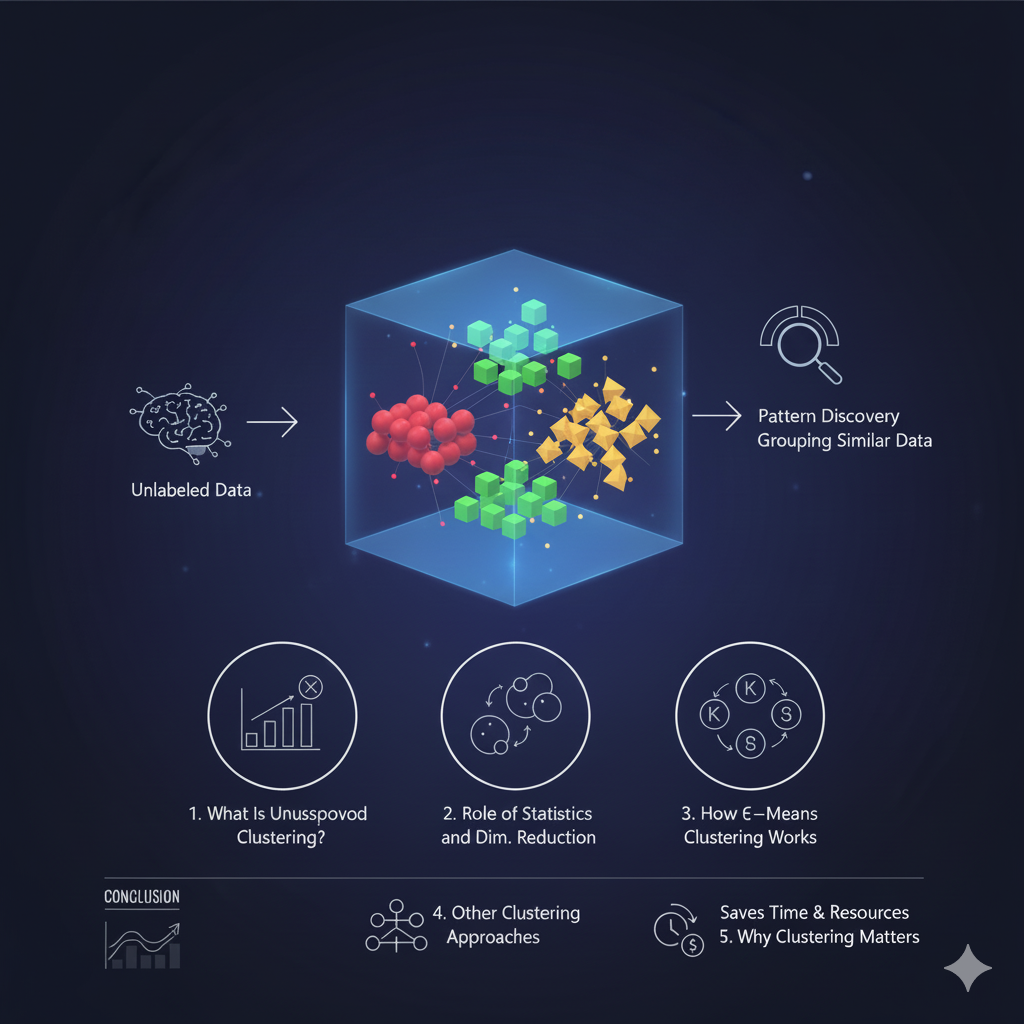
Not all machine-learning problems come with labeled data. In many real-world cases, we only have raw information without knowing the correct answers. This is where unsupervised learning becomes useful. One of the most common unsupervised techniques is clustering, which helps identify natural patterns and group similar data points together.
🔍 1. What Is Unsupervised Clustering?
Unsupervised clustering works without labeled outputs.
• 🎯 The goal is to group similar data points based on shared features
• 🤝 Data within the same cluster is more alike
• 🔀 Data in different clusters is more distinct
Clustering is widely used for data exploration, pattern discovery, and organizing large datasets.
📊 2. Role of Statistics and Dimensionality Reduction
Basic statistics such as mean and variance provide useful summaries of unlabeled data.
For larger and more complex datasets, techniques like Principal Component Analysis (PCA) are often used:
• 📉 PCA reduces the number of variables
• ⭐ It keeps the most important patterns
• ⚡ It makes clustering faster and easier
⚙️ 3. How K-Means Clustering Works
K-means is one of the most popular clustering algorithms.
• 🔢 A fixed number of clusters (k) is chosen
• 📍 Each data point is assigned to the nearest cluster center
• 🔄 Cluster centers are updated repeatedly
• ⏳ The process continues until clusters stabilize
Choosing the correct value of k often requires experimentation.
🧩 4. Other Clustering Approaches
Another common method is hierarchical clustering.
• 🪜 Clusters are built step by step
• 🌳 Relationships between groups become clear
• 🐢 Useful when understanding data structure is more important than speed
💡 5. Why Clustering Matters
Clustering is especially helpful when labeling data is expensive or time-consuming.
• 🏷️ Reduces the need for manual labeling
• ⏱️ Saves time and resources
• 🔍 Helps uncover hidden patterns in large datasets
✅ Conclusion
Unsupervised clustering is a powerful tool for discovering structure in data. By grouping similar data points, it enables better insights and supports many real-world machine-learning applications. 🚀
See more blogs
You can all the articles below