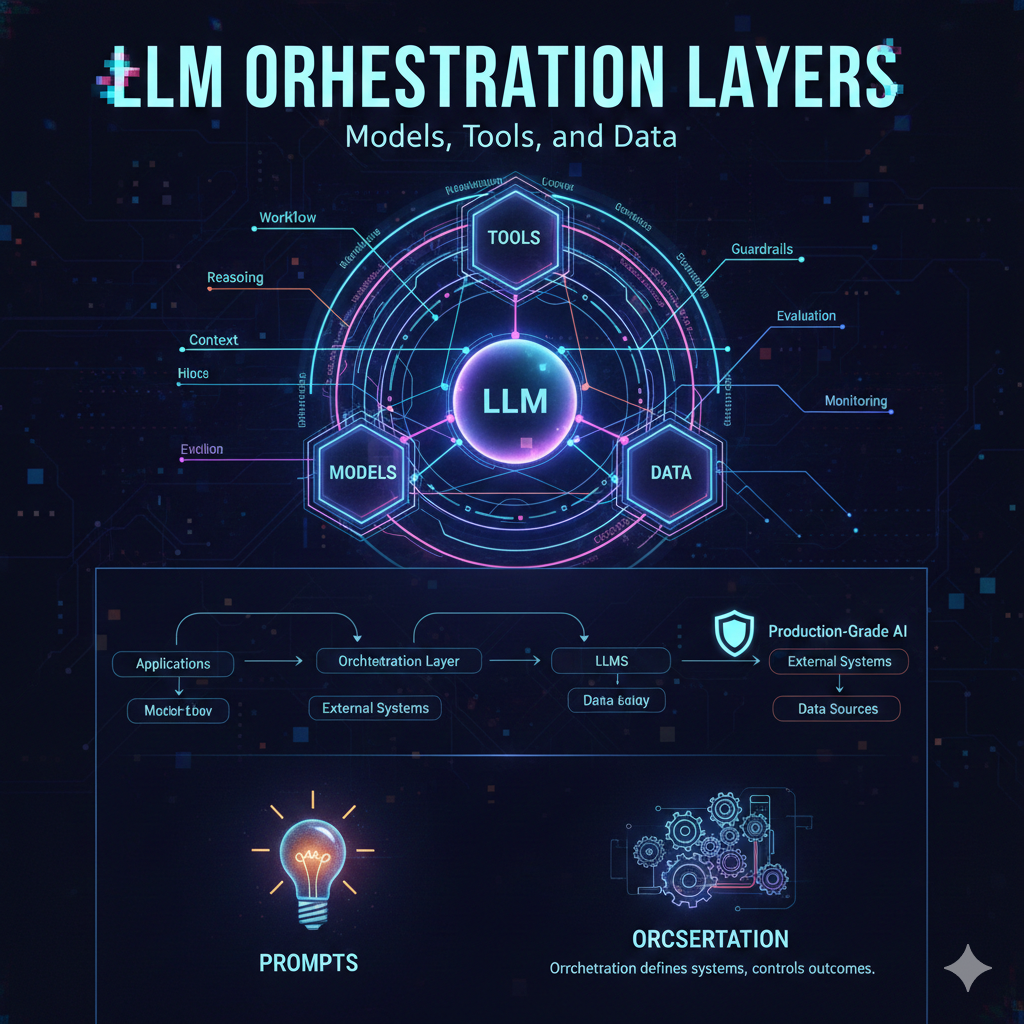
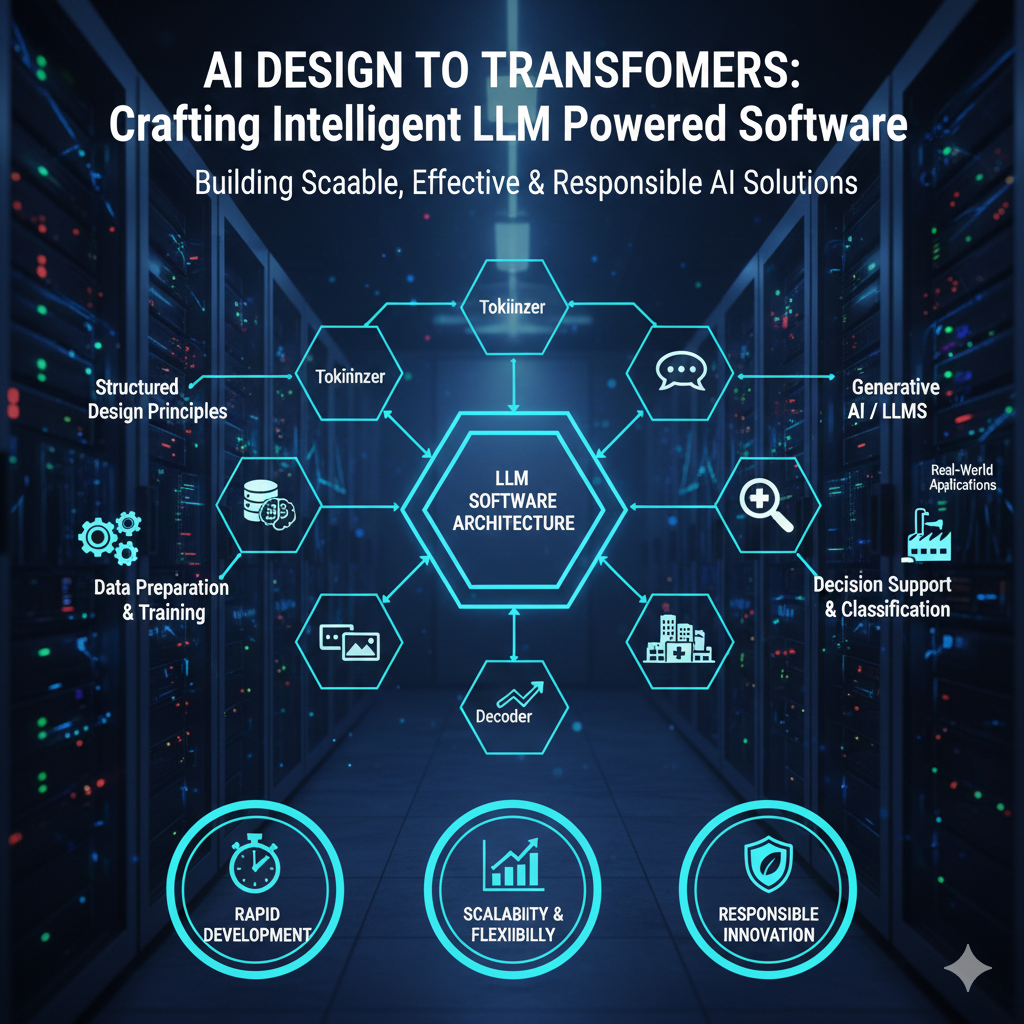
How Convolutional Neural Networks Enable Multimodal LLM

How Convolutional Neural Networks Enable Multimodal LLM 🧠
Large Language Model (LLM) software has moved beyond text-only capabilities. Modern AI systems now work with images, documents, charts, and other visual content alongside language. Convolutional Neural Networks (CNNs) are a core technology that allows LLM platforms to interpret and use visual information effectively 🖼️🤖
1. The Role of CNNs in Multimodal AI 👁️
Visual data contains spatial relationships that traditional models struggle to capture. CNNs are specifically designed to process this structure 📐
• They identify patterns such as edges, shapes, and textures ✏️
• They maintain spatial context within images 🗺️
• They require fewer parameters than fully connected networks ⚙️
Within LLM systems, CNNs serve as the visual processing layer that converts raw images into usable signals 🔄
2. How CNNs Learn Visual Patterns 🔍
CNNs analyze data using small, learnable filters 🧠
• Filters move across localized regions of an image 🔄
• Each filter specializes in detecting a specific visual feature 🎯
• Non-linear functions enhance the model’s ability to learn complex patterns 📈
This design enables CNNs to recognize features consistently, regardless of their position in the image 📸
3. Connecting Visual Data with Language Models 🔗
In multimodal LLM architectures, CNN outputs are combined with text-based models 🧩📘
• Visual information is transformed into structured embeddings 📊
• These embeddings align with language representations 🗣️
• The system can reason across visual and textual inputs 🧠
This integration supports applications like document analysis, visual search, and image-based question answering 📄🔎
4. Scaling CNNs for Production LLM Platforms ⚙️
Real-world AI systems rely on advanced CNN techniques to maintain performance and accuracy 🚀
• Multiple filters capture a wide range of visual details 🎨
• Pooling layers emphasize the most relevant features 📌
• Normalization layers improve training consistency ⚖️
• Flattened outputs connect vision models to language pipelines 🔗
Modern AI frameworks optimize these processes using high-performance hardware 💻
Conclusion 🎯
Convolutional Neural Networks are essential to multimodal LLM software. By extracting meaningful visual features and integrating them with language models, CNNs enable AI systems to understand images, documents, and visual context at scale. As LLM platforms continue to expand beyond text, CNNs remain a foundational component for building intelligent, multimodal AI solutions 🌍🤖
See more blogs
You can all the articles below