Decoupling Reasoning, Retrieval, and Execution in LLM Systems
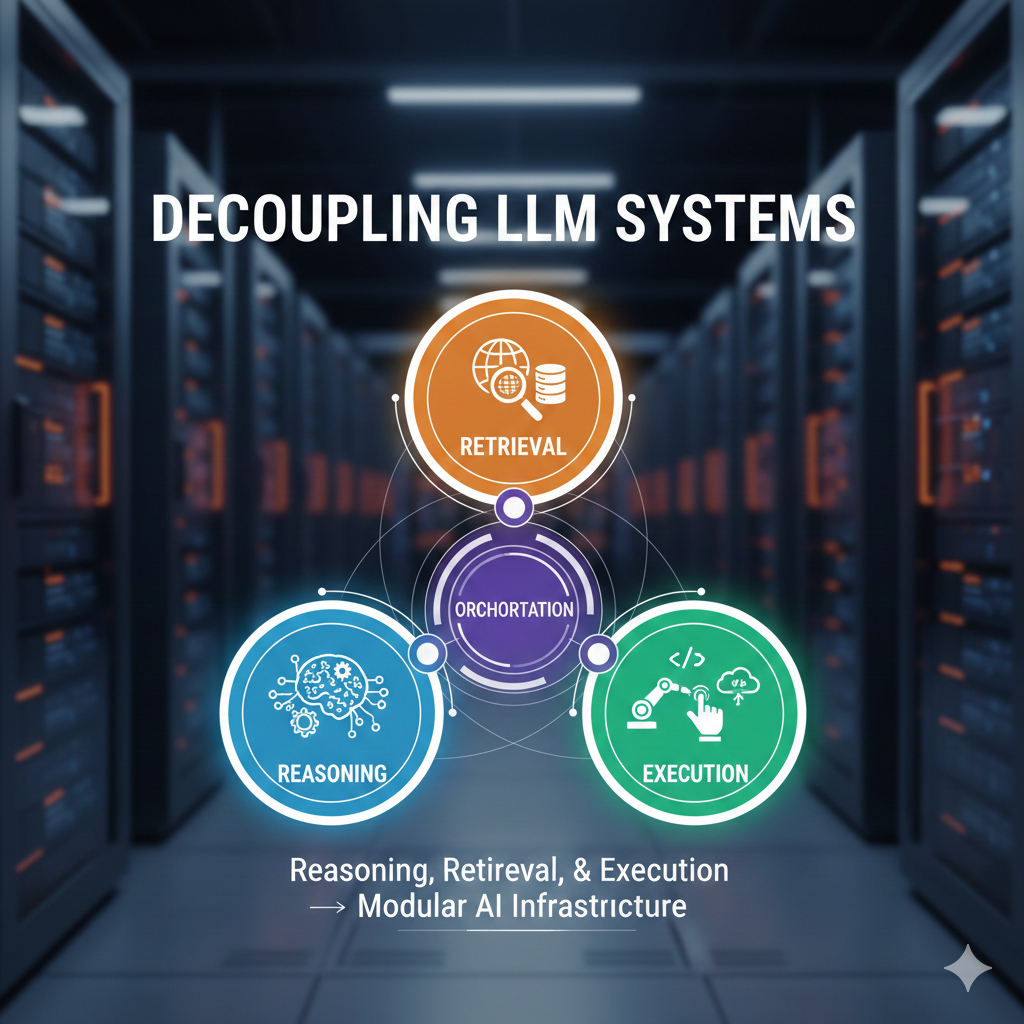
Decoupling Reasoning, Retrieval, and Execution in LLM Systems
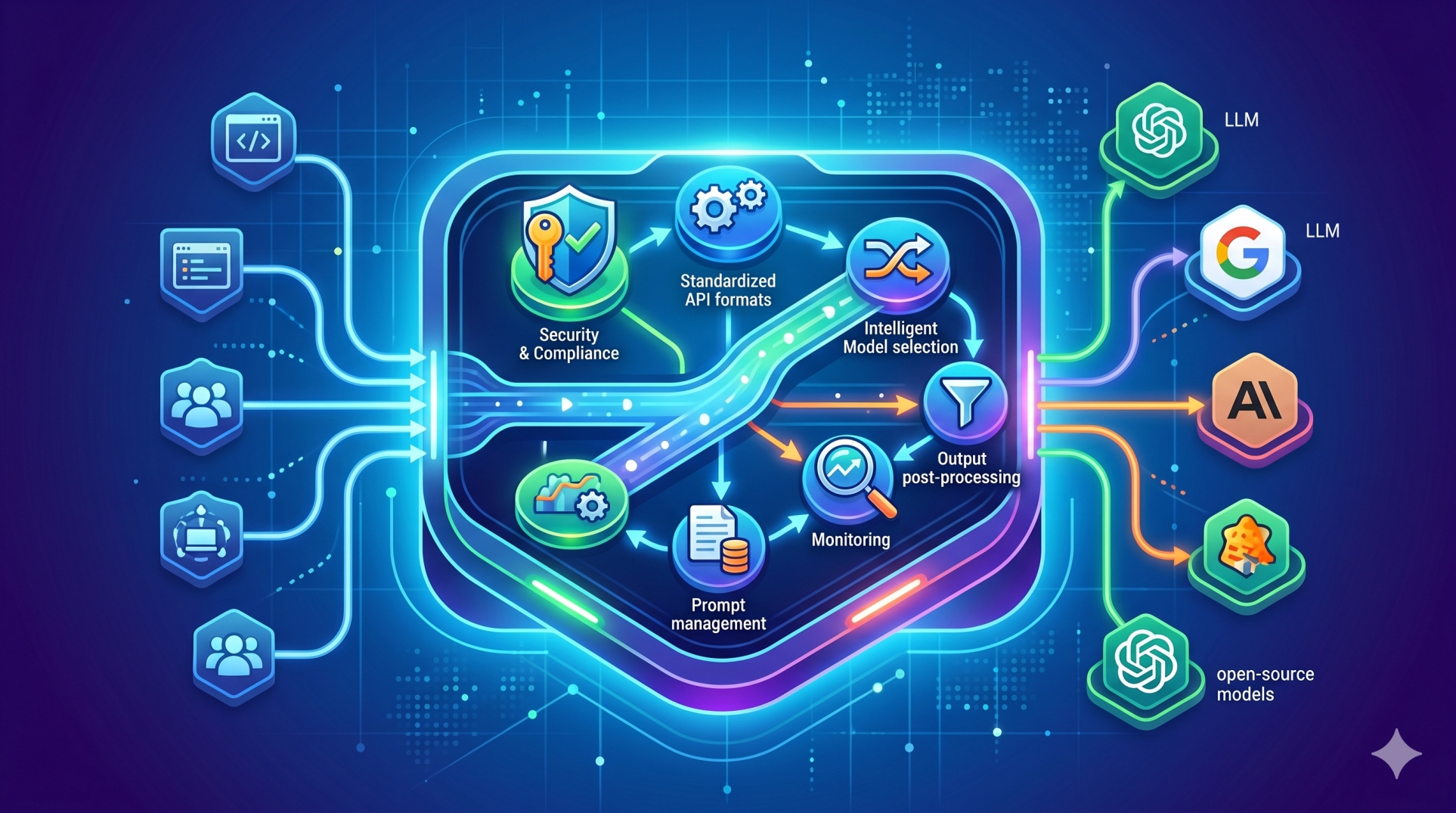
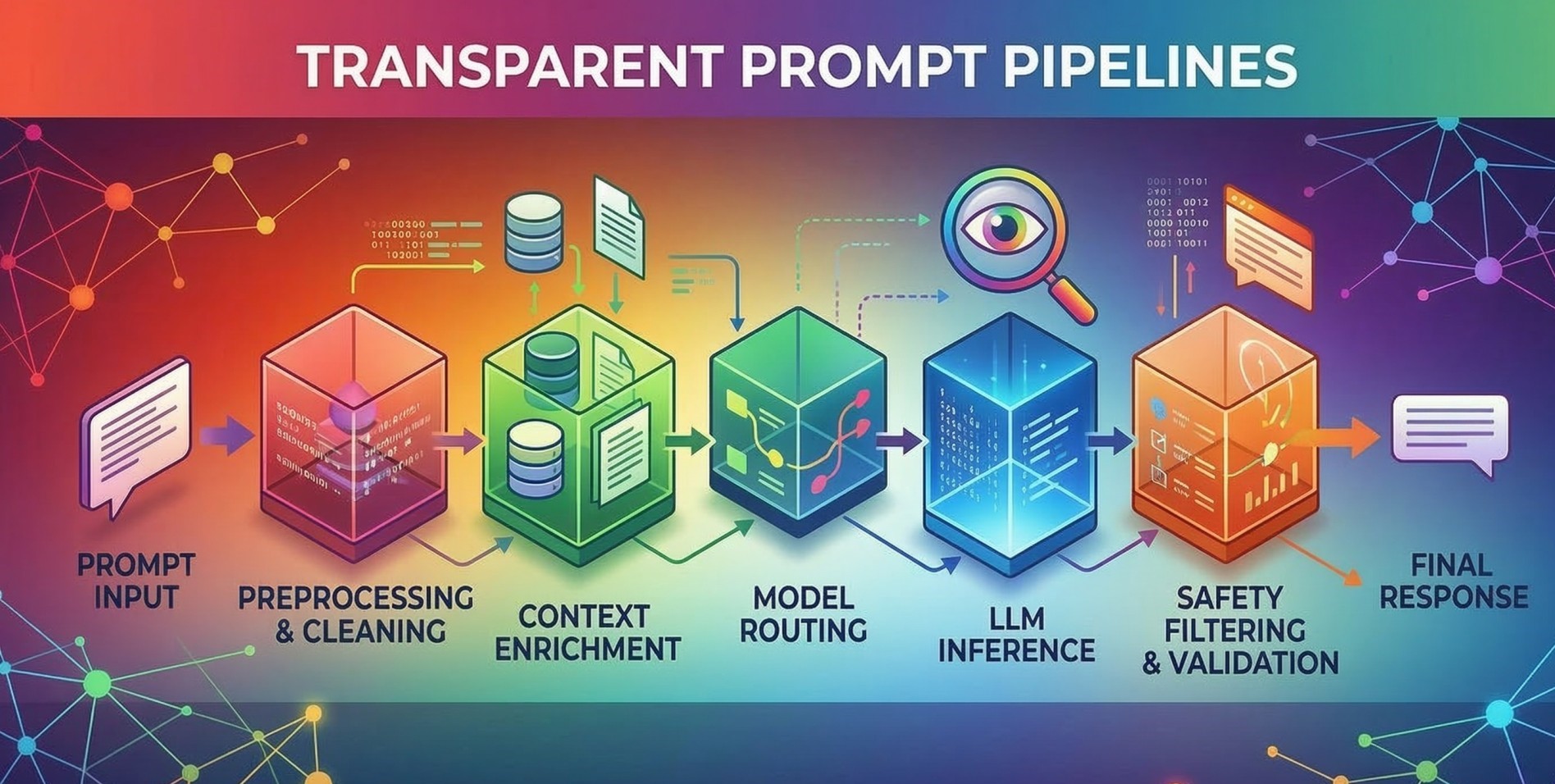
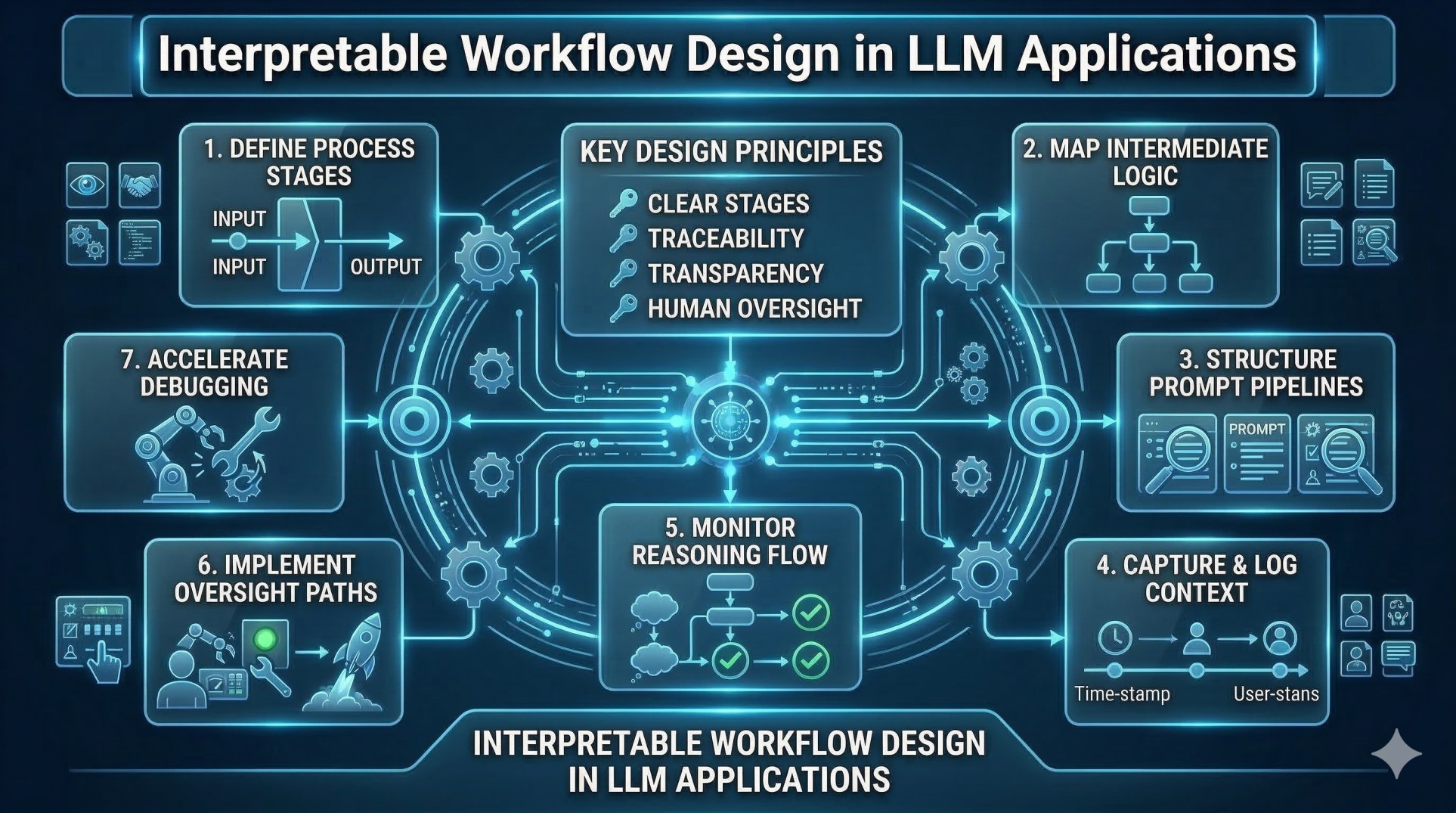
As LLM systems evolve from simple prompt-driven tools into full-scale application infrastructures, architecture becomes a defining factor in performance and sustainability. A key advancement in modern LLM engineering is the separation of reasoning, retrieval, and execution into distinct layers. This modular approach enhances scalability, observability, security, and long-term adaptability while enabling more controlled and predictable AI behavior.
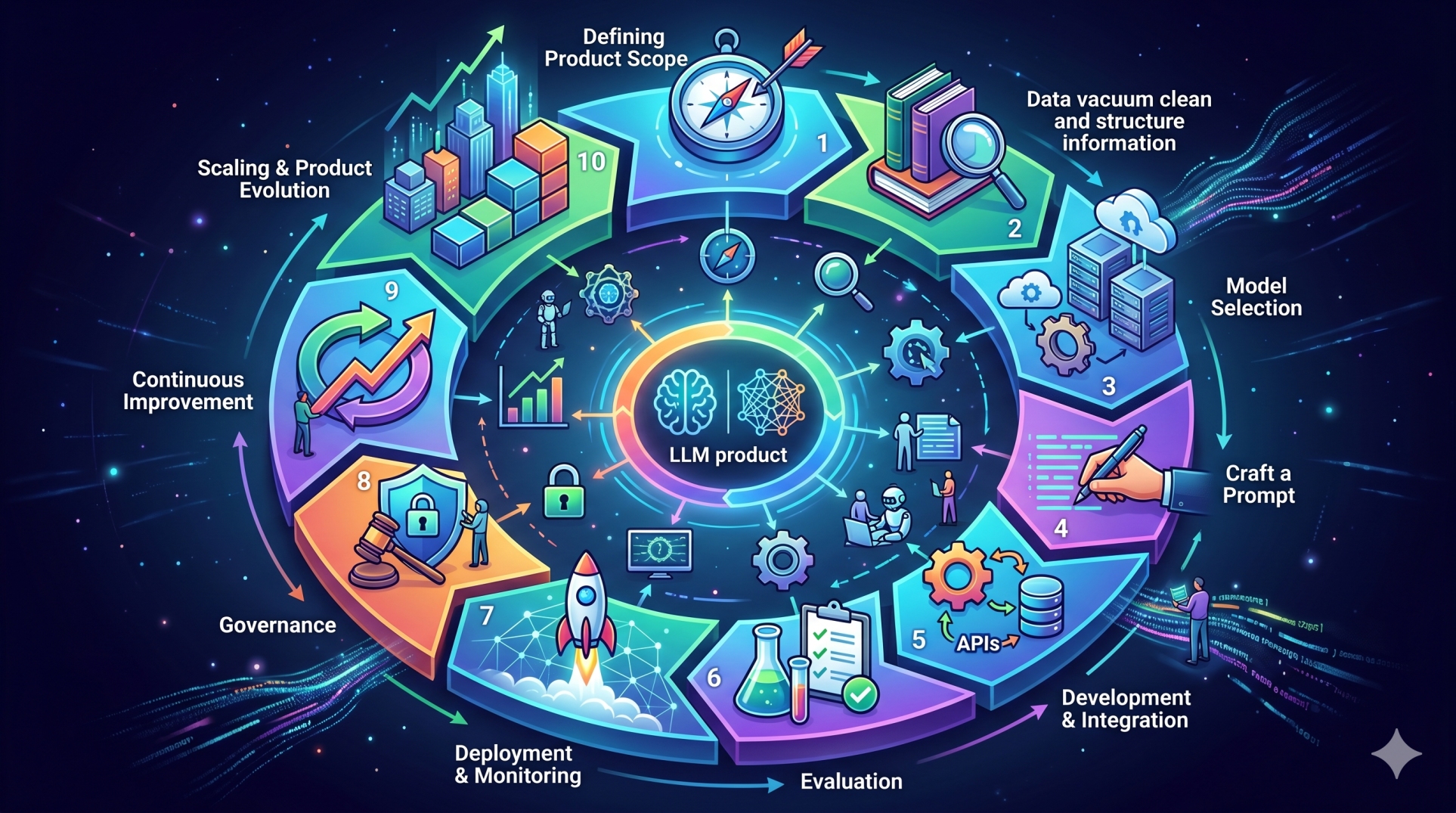
Step 1: Understanding the Three Core Functions 🧠
• Reasoning manages logical inference, planning, and structured decision-making 🔍
• Retrieval supplies relevant external knowledge and contextual information 📚
• Execution carries out actions such as API requests, database operations, or workflow automation ⚙️
• Each function operates under different latency, accuracy, and reliability constraints 📊
• Combining them tightly reduces transparency and architectural clarity 🚧
Step 2: Why Monolithic LLM Architectures Break Down ⚠️
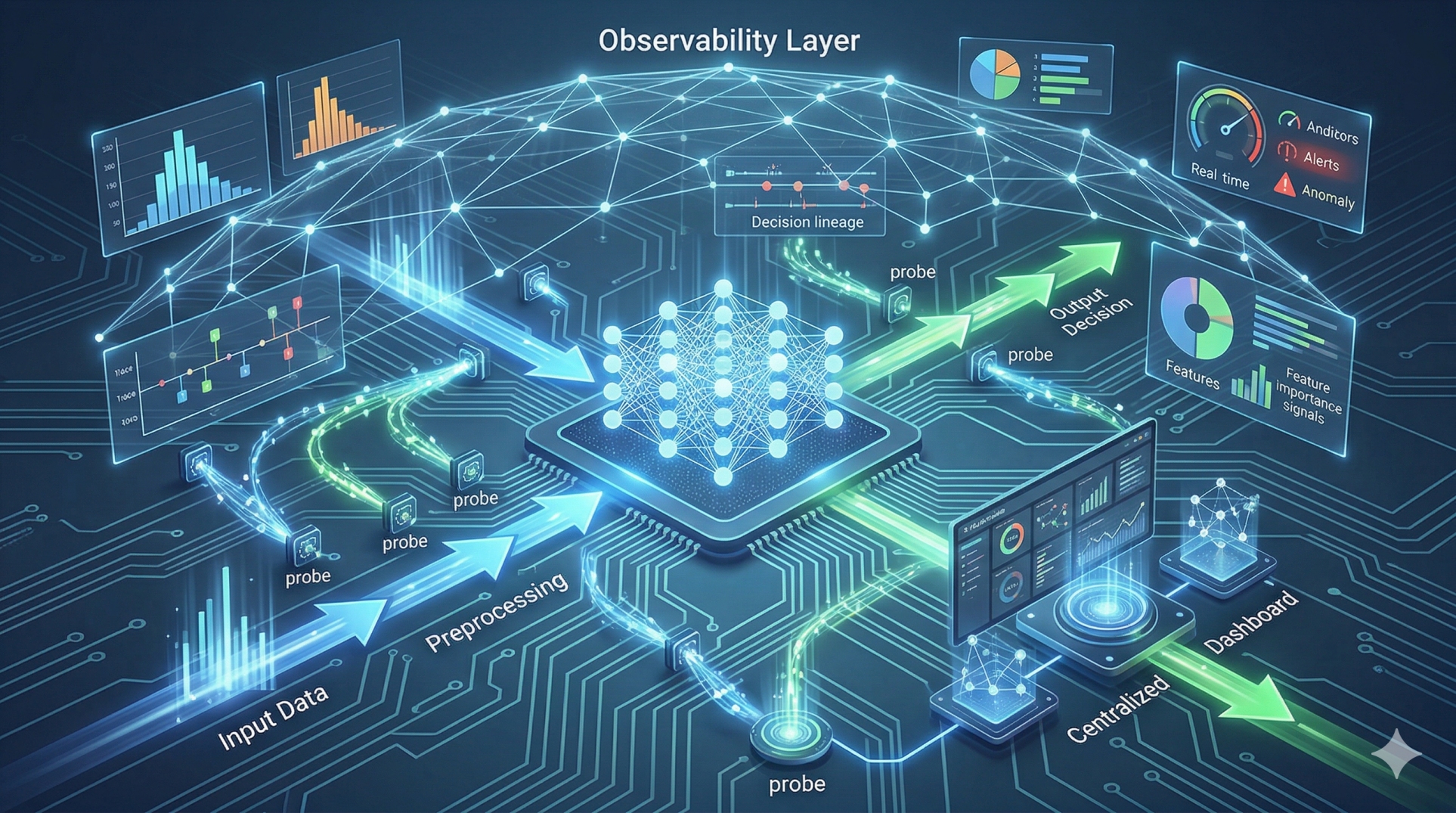
• Unified pipelines are difficult to monitor and troubleshoot 🔎
• Failures become harder to isolate across thinking and action layers 🧩
• Scaling costs rise when all tasks depend on a single model tier 💰
• Embedding execution privileges within prompts increases security exposure 🔐
• Architectural rigidity limits future system evolution 🔄
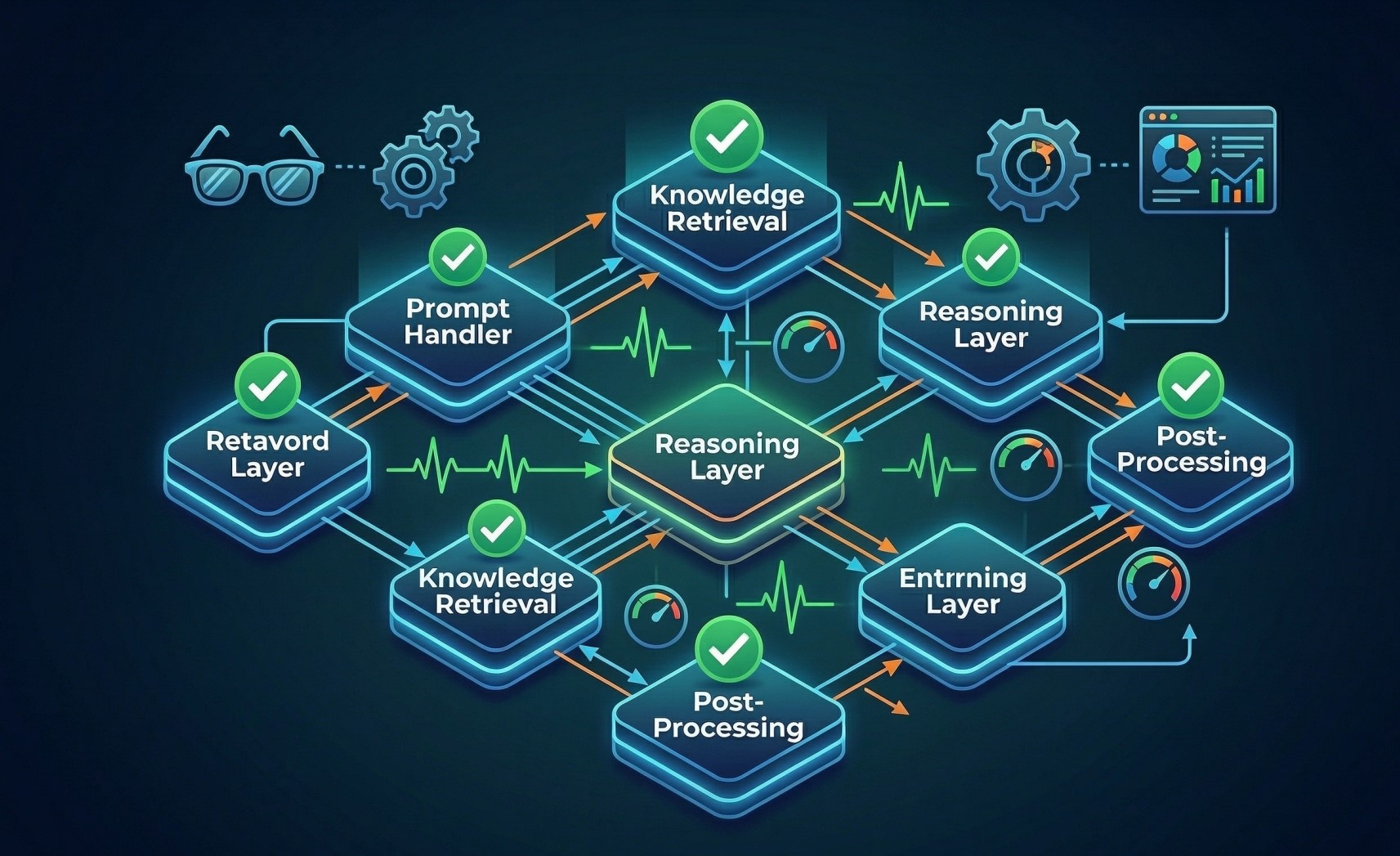
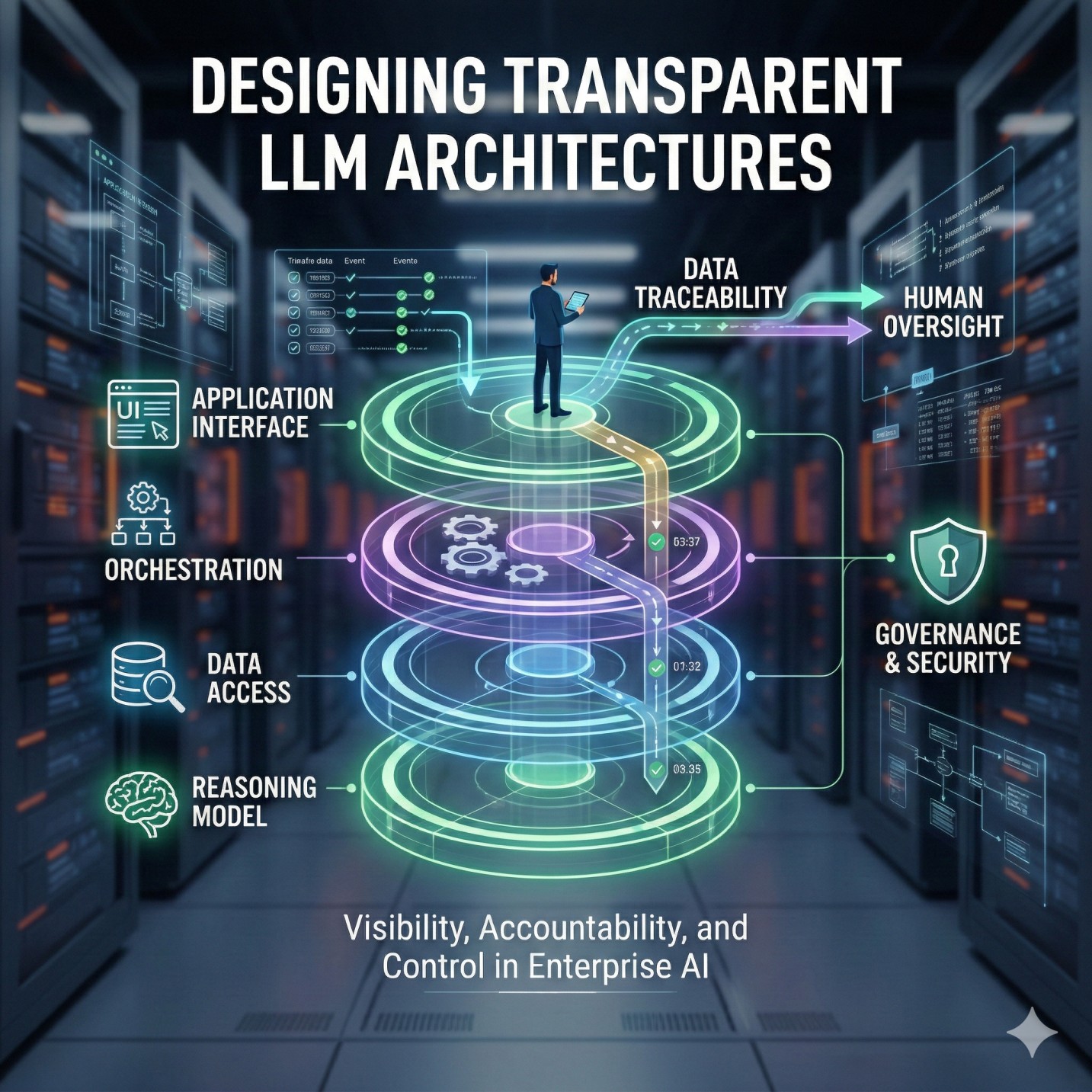
Step 3: Separating the Reasoning Layer 🧠
• Decouples cognitive processing from system-level access 🚫
• Enables deployment of reasoning-optimized or specialized models 🎯
• Produces explicit plans and intermediate outputs for transparency 📄
• Enhances auditability of logic and decision pathways 📋
• Supports continuous improvement of reasoning quality independent of other layers 🔁
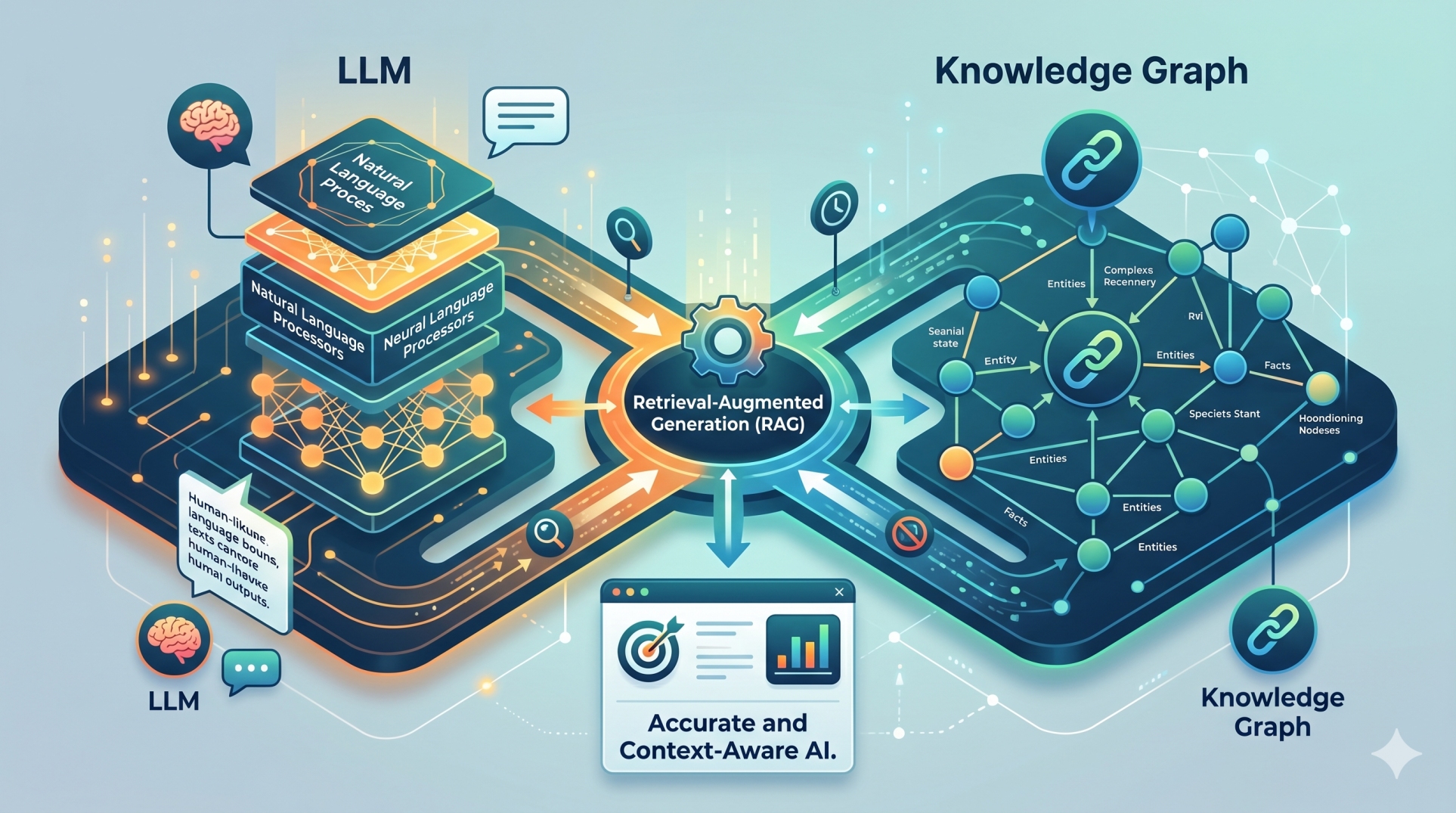
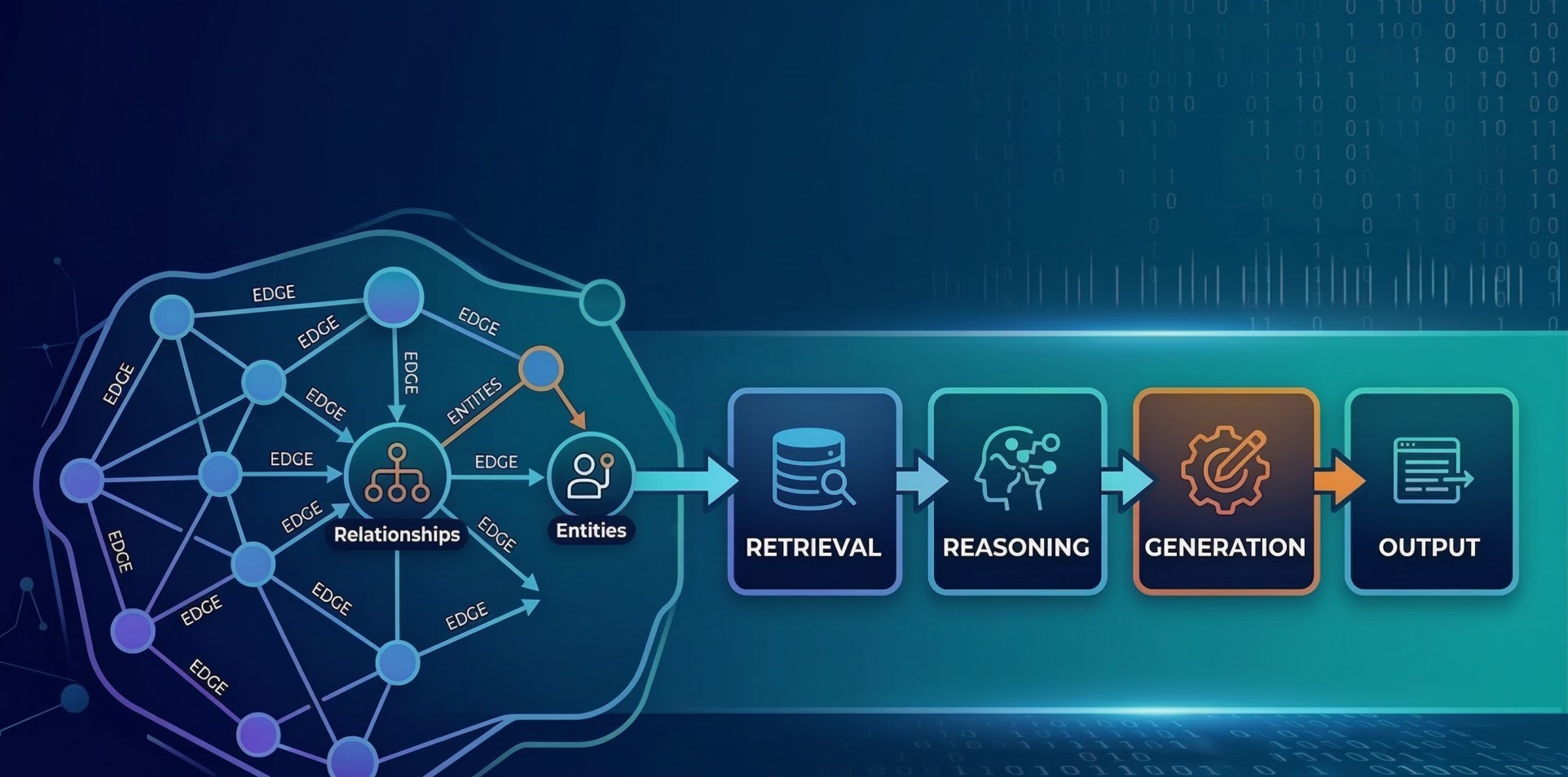
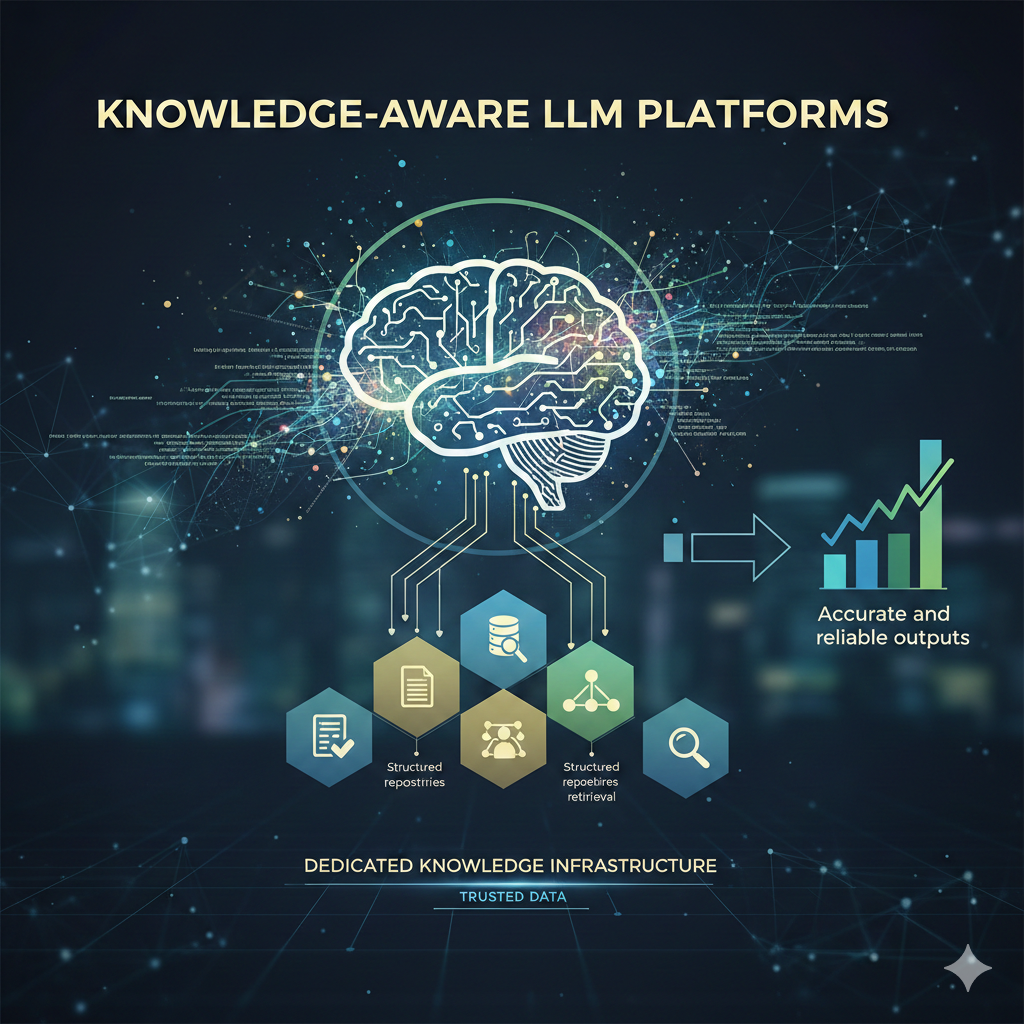
Step 4: Designing the Retrieval Layer Independently 📚
• Interfaces with vector databases and structured knowledge repositories 🗂️
• Injects dynamic context without altering core reasoning logic 🔗
• Strengthens factual grounding and reduces hallucination risks ✔️
• Allows independent refinement of ranking and search algorithms 🔍
• Separates knowledge access from cognitive computation 🧩
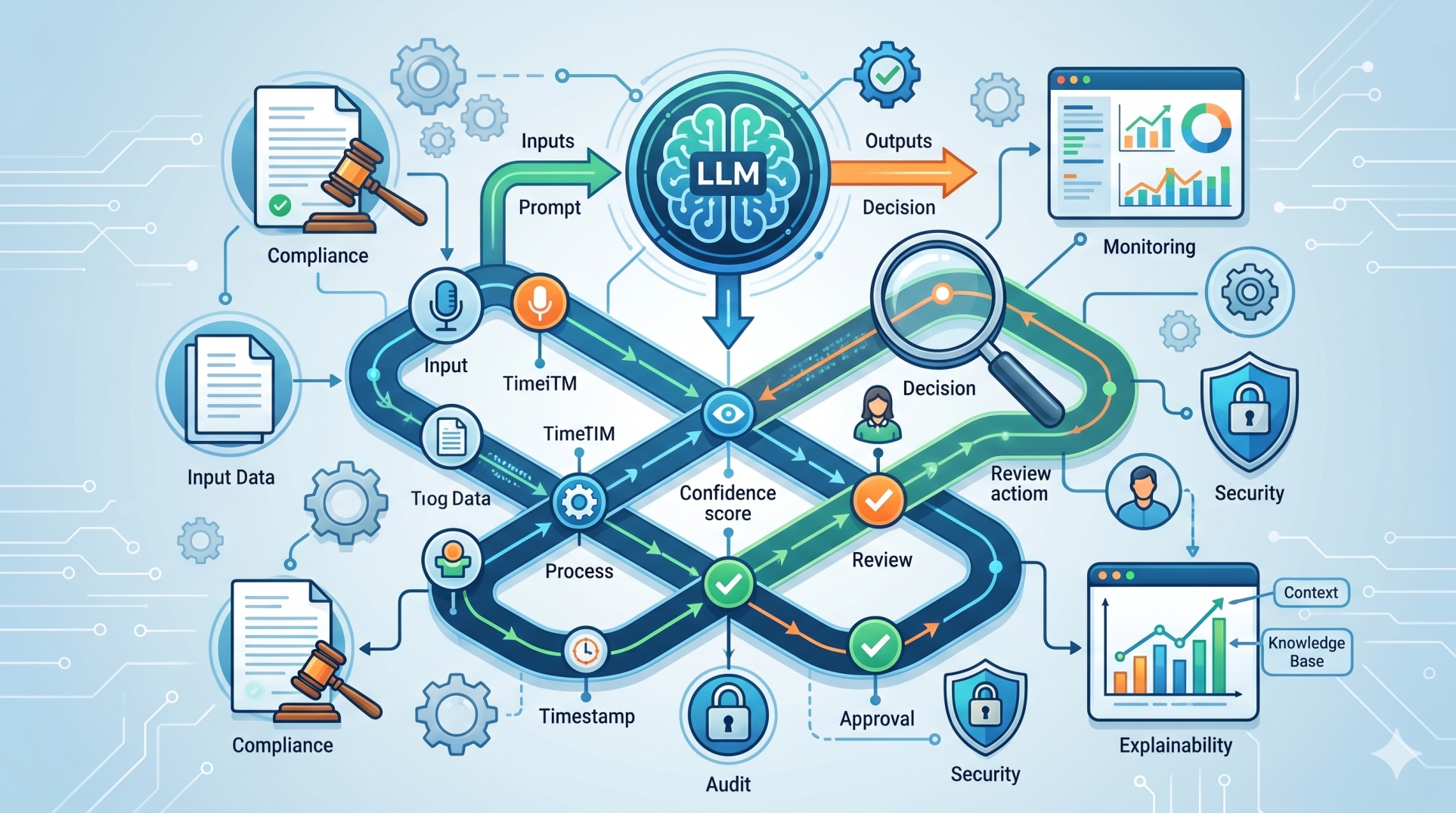
Step 5: Isolating the Execution Layer ⚙️
• Manages tool invocation, API interactions, and operational tasks 🛠️
• Enforces permission boundaries and validation safeguards 🛡️
• Minimizes risk of unintended or unsafe system actions ⚠️
• Enables deterministic workflows following reasoning approval ✔️
• Improves production reliability through controlled action handling 📈
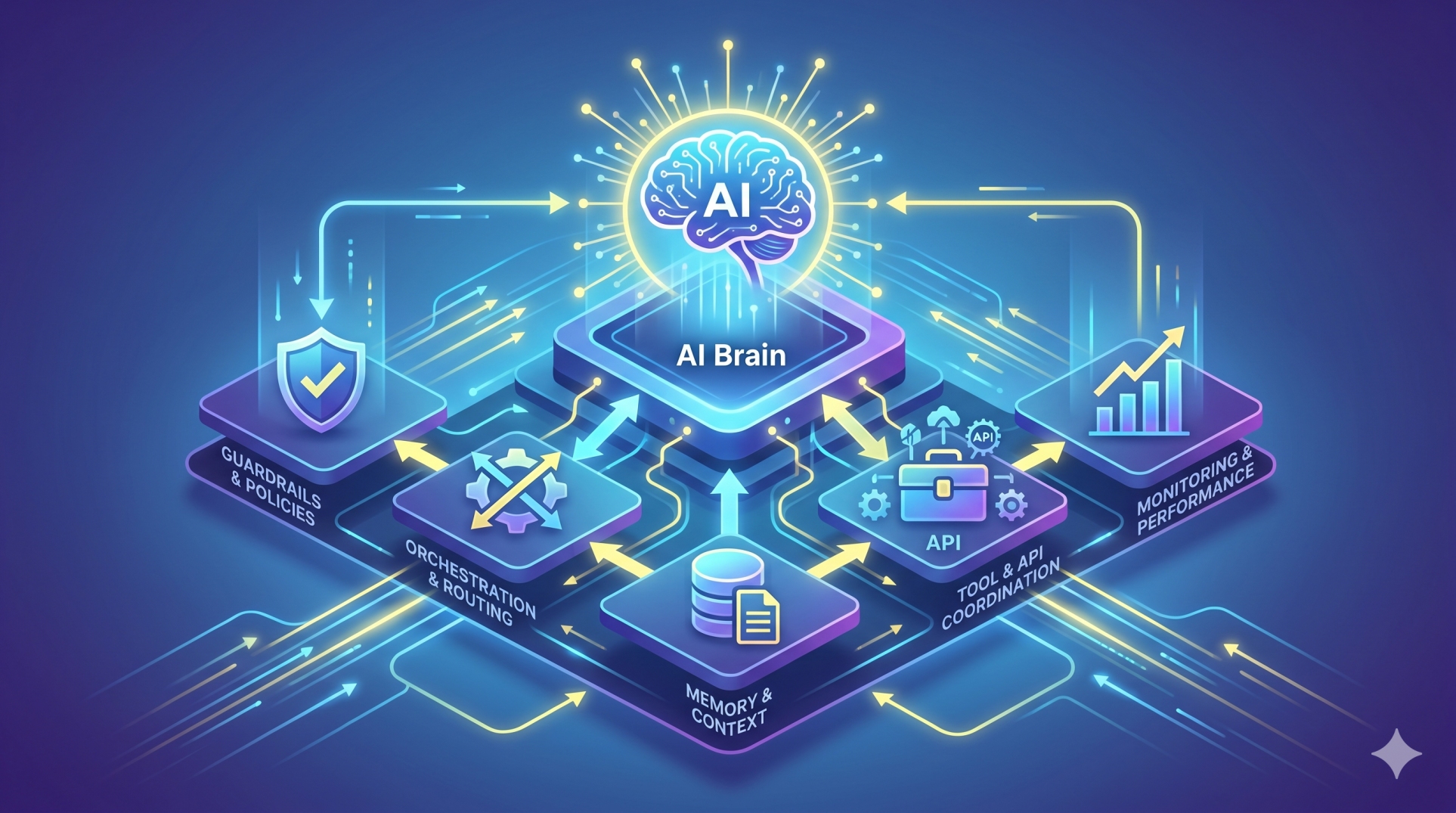
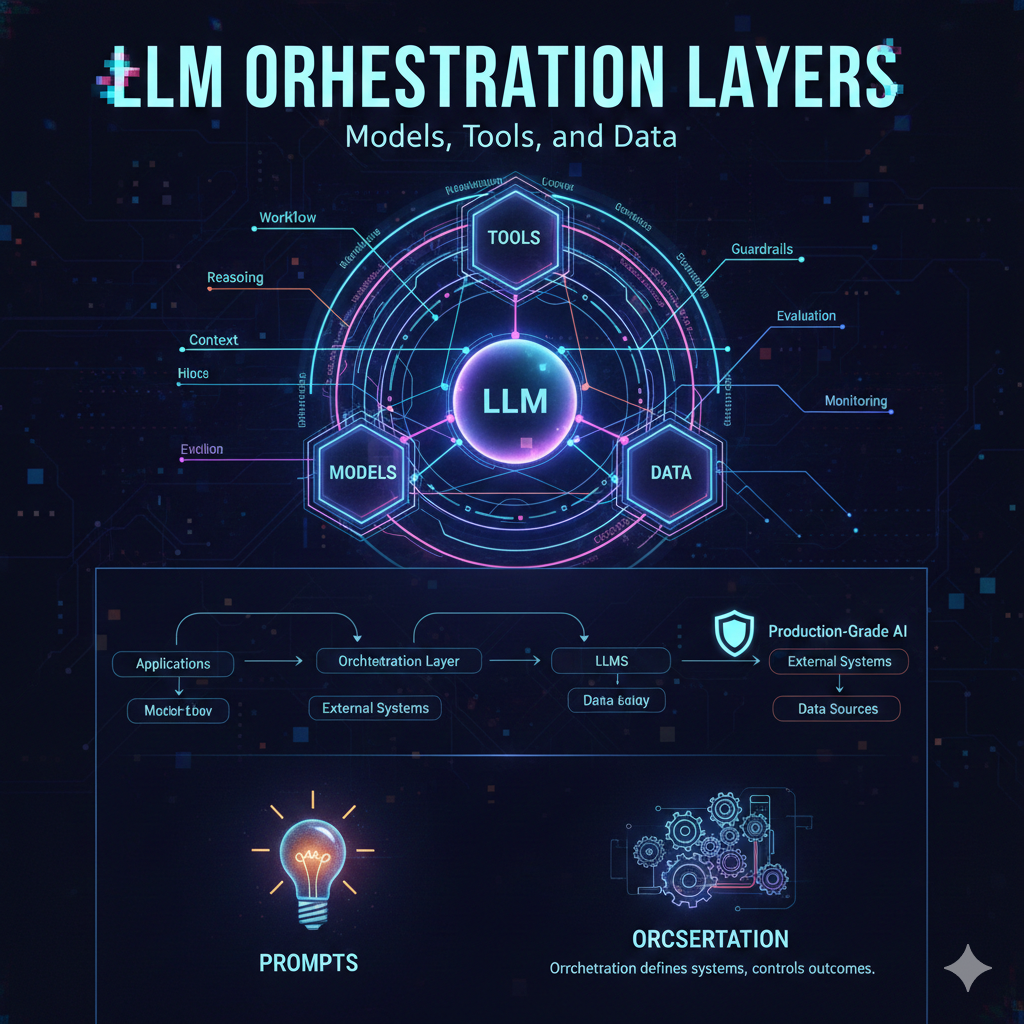
Step 6: Orchestration as the Control Plane 🎛️
• Coordinates communication between reasoning, retrieval, and execution layers 🔄
• Maintains state across complex, multi-step workflows 📌
• Records intermediate outputs for monitoring and evaluation 📊
• Applies guardrails before initiating external operations 🛑
• Facilitates modular upgrades without disrupting the full system 🔧
Step 7: Benefits of Decoupled LLM Architectures 🚀
• Scales efficiently through component-level optimization 📈
• Improves debugging and operational visibility 🔍
• Establishes stronger security boundaries between thought and action 🔐
• Reduces costs by assigning tasks to appropriately sized models 💡
• Accelerates experimentation with minimal system-wide risk 🔬
Step 8: Strategic Impact of Decoupling 🏗️
• Delivers enterprise-grade reliability and governance structures 🏢
• Enables secure automation across large-scale environments 🤖
• Prepares systems for evolving models, tools, and integrations 🔄
Step 9: Implications for Production Deployment 📦
• Requires clearly defined interfaces between system layers 🔗
• Depends on comprehensive logging and monitoring frameworks 📊
• Benefits from standardized inter-component communication protocols 🧾
• Supports isolated A/B testing of reasoning, retrieval, or execution components 🧪
• Aligns architecture with long-term platform strategy 🧭
Step 10: Moving Toward Modular AI Infrastructure 🏛️
• Encourages composable and flexible AI system design 🧩
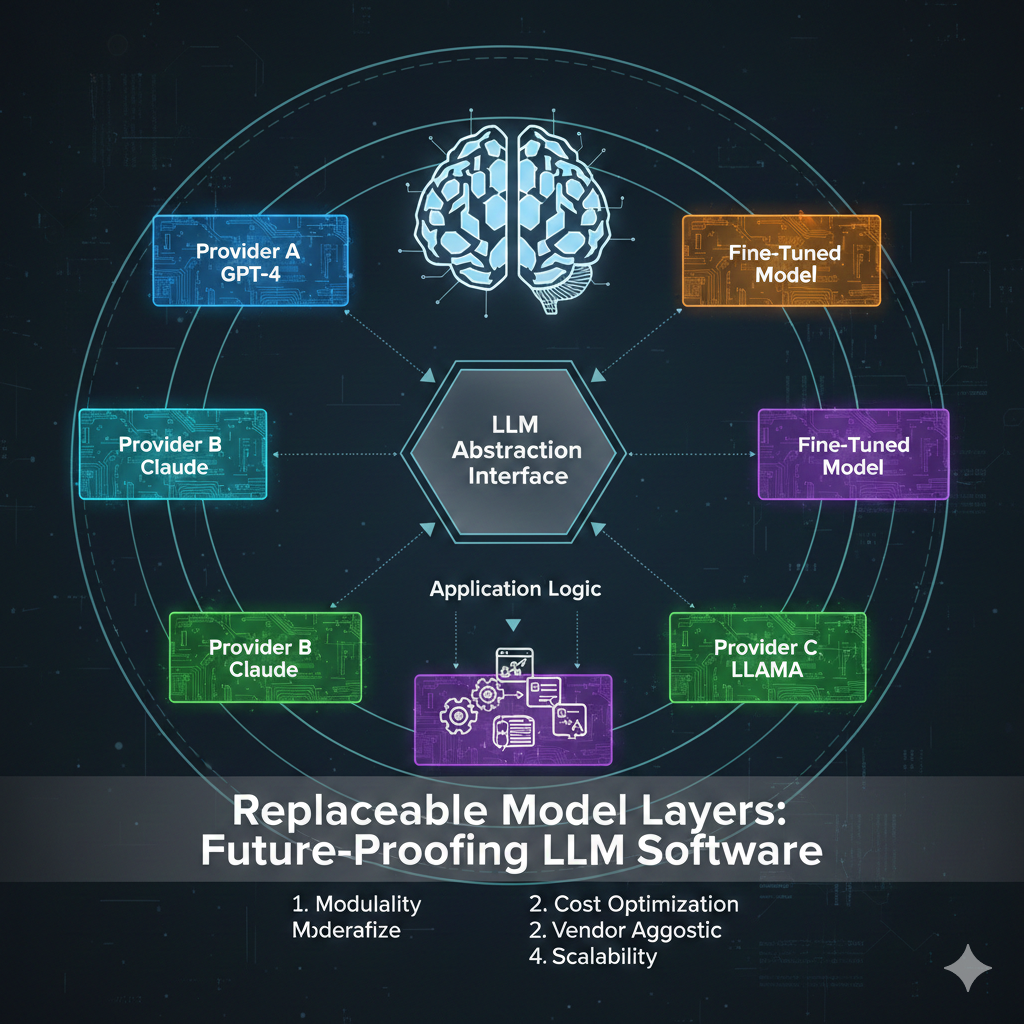
• Enables independent advancement of models and data systems 🔄
• Reduces vendor dependency by abstracting critical functions 🔓
• Simplifies maintenance as system complexity increases 🛠️
• Establishes the groundwork for next-generation AI platforms 🌐
Conclusion
Separating reasoning, retrieval, and execution transforms LLM systems from tightly coupled pipelines into modular, resilient platforms. By isolating cognitive processing, knowledge access, and operational actions into clearly defined layers, organizations gain stronger control, improved security, and greater scalability. This architectural evolution is fundamental for deploying production-grade AI systems capable of handling sophisticated, real-world workflows.
See more blogs
You can all the articles below