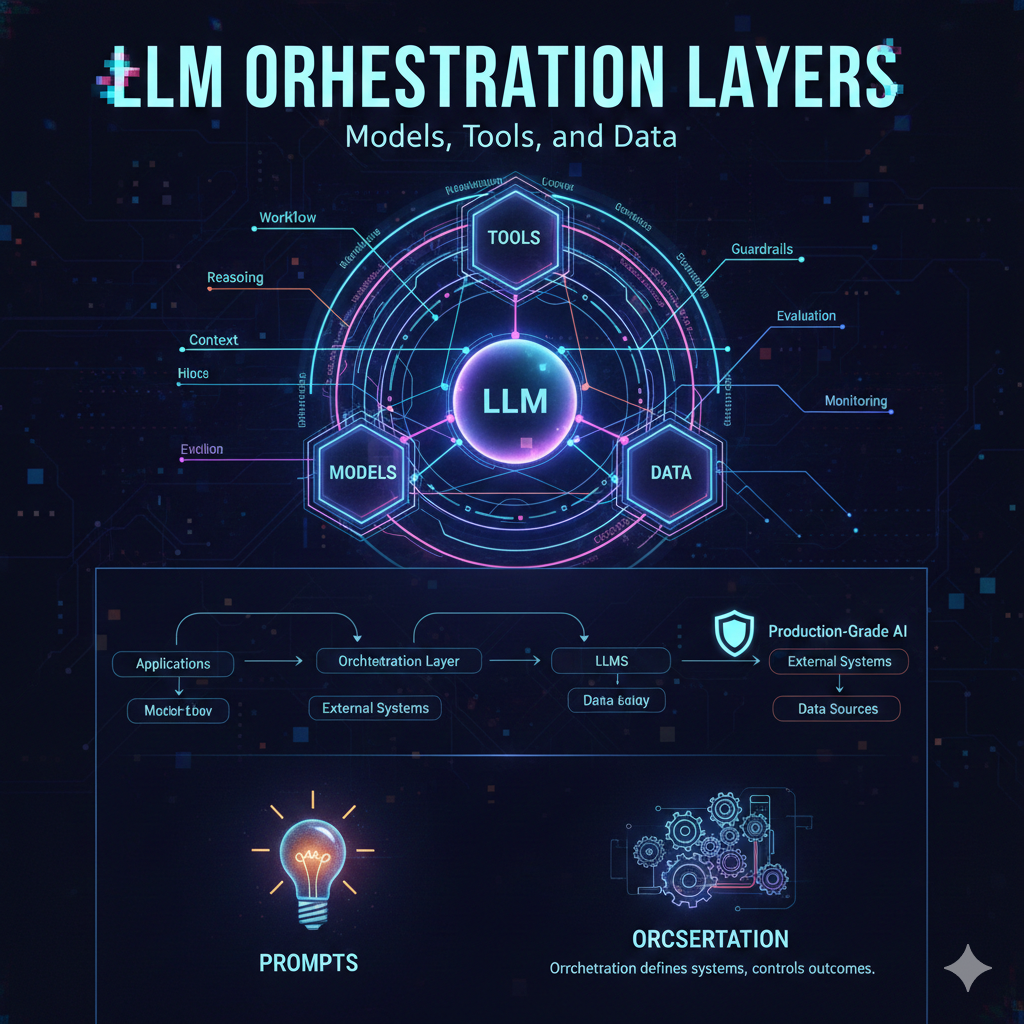
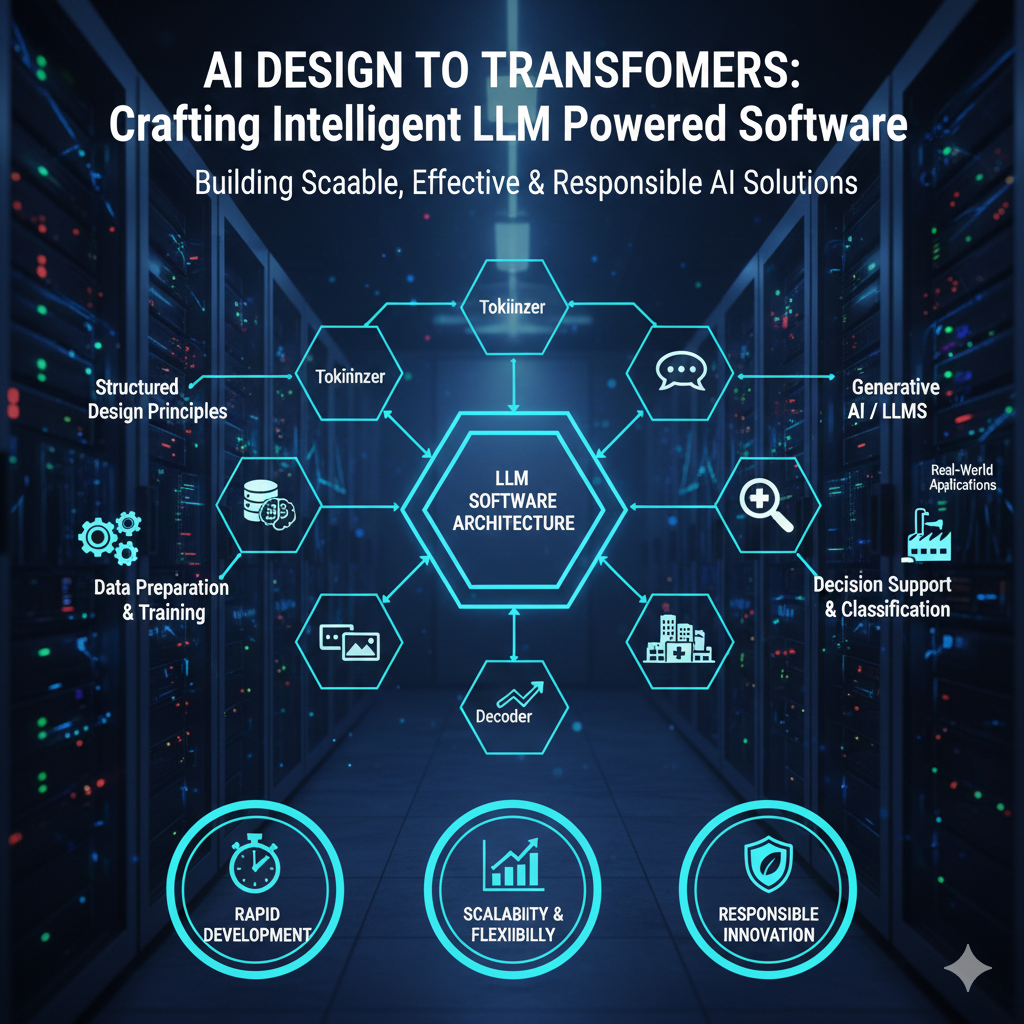
Cost-Aware Architectures for LLM Applications

Cost-Aware Architectures for LLM Applications
As Large Language Model solutions transition from pilot projects to production-grade systems, financial efficiency becomes a defining architectural priority. Usage-based pricing, infrastructure demands, latency constraints, and scaling strategies all influence long-term viability. Designing cost-aware LLM architectures ensures that intelligent applications remain economically sustainable while delivering measurable business impact.
Step 1: Identifying Primary Cost Factors in LLM Systems 💰
• Token usage across both input prompts and generated outputs 🔢
• Pricing differences between model tiers and providers 🏷️
• Volume and frequency of inference requests 📊
• Size of context windows and memory allocation 🧠
• Compute, orchestration, and infrastructure expenses ⚙️
Step 2: Selecting the Right Model for Each Task 🎯
• Align model capability with task complexity ⚖️
• Deploy smaller models for predictable, structured workloads 📦
• Use advanced models selectively for reasoning-intensive scenarios 🧩
• Balance output quality with financial constraints 📉
• Regularly evaluate performance-to-cost efficiency 📈
Step 3: Optimizing Prompts to Reduce Overhead ✂️
• Eliminate unnecessary context and verbosity 📝
• Provide only task-relevant information 🎯
• Use structured formatting to control response length 📏
• Establish token limits and budgeting practices 💳
• Maintain consistent prompt templates for predictable usage 📋
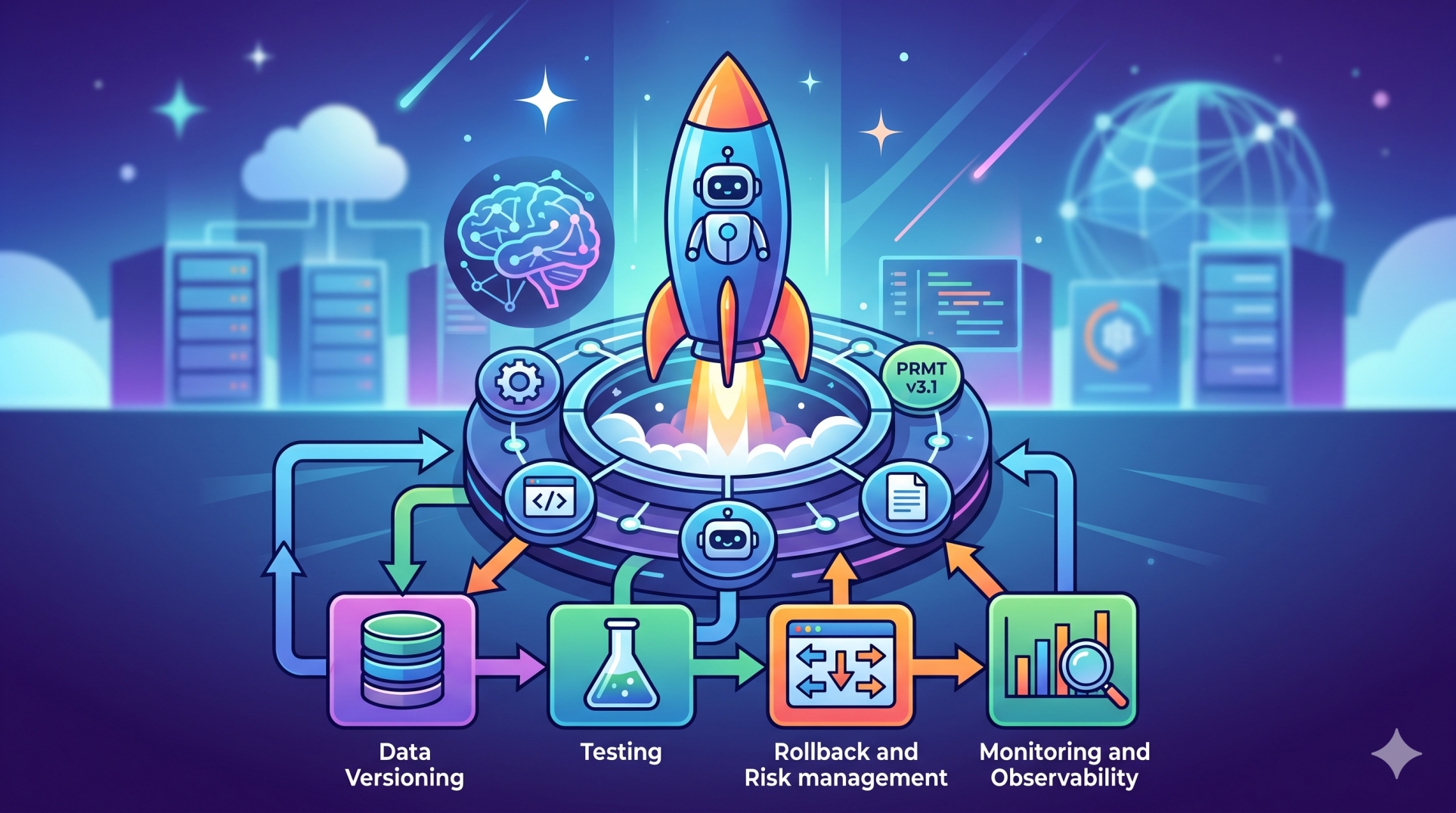
Step 4: Leveraging Caching and Reusability ♻️
• Store frequently generated responses for reuse 💾
• Cache embeddings for recurring semantic queries 🗂️
• Apply similarity matching to prevent redundant calls 🔁
• Minimize repeated inference for identical requests 🚫
• Improve response time while lowering operational cost ⚡
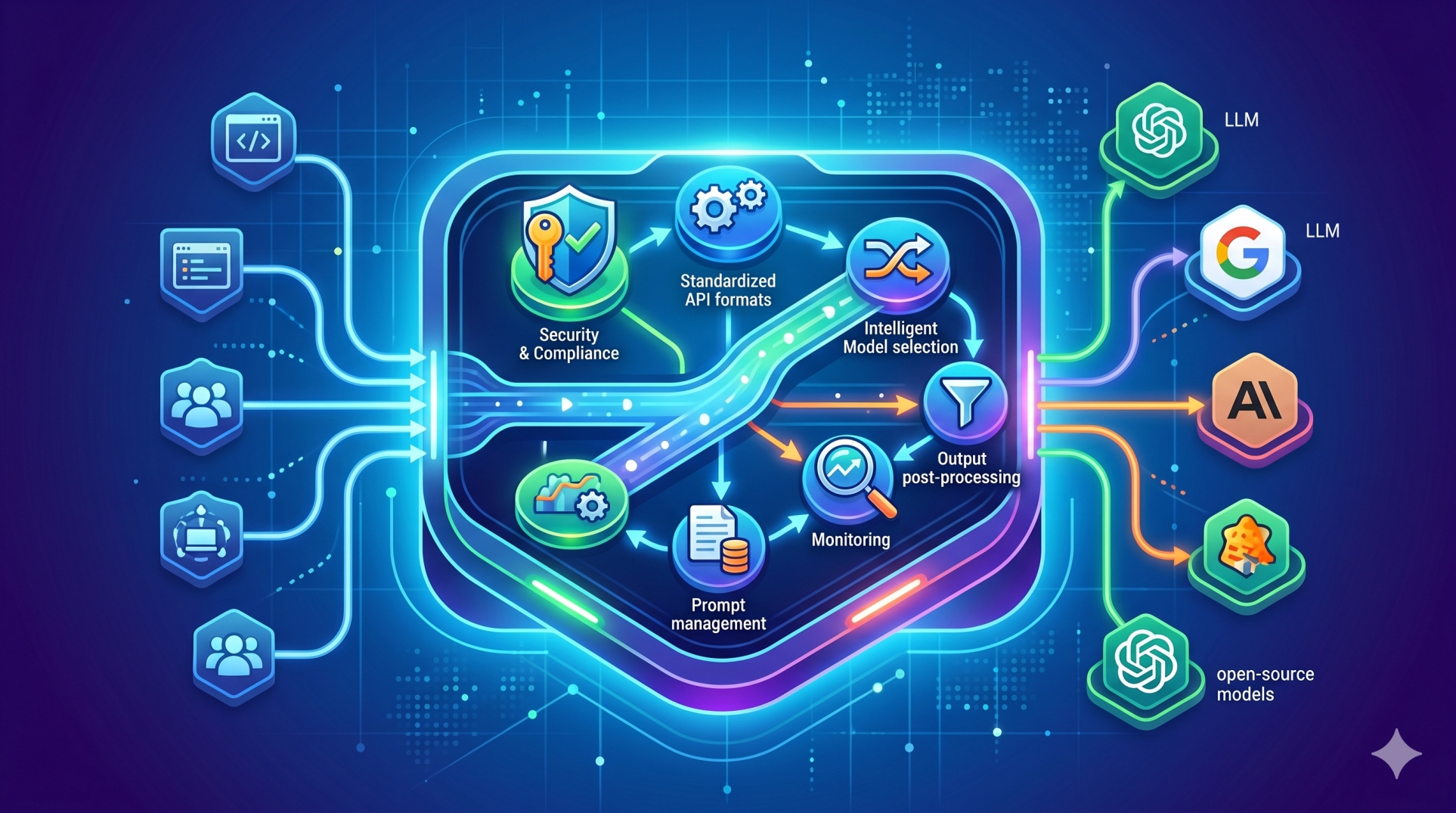
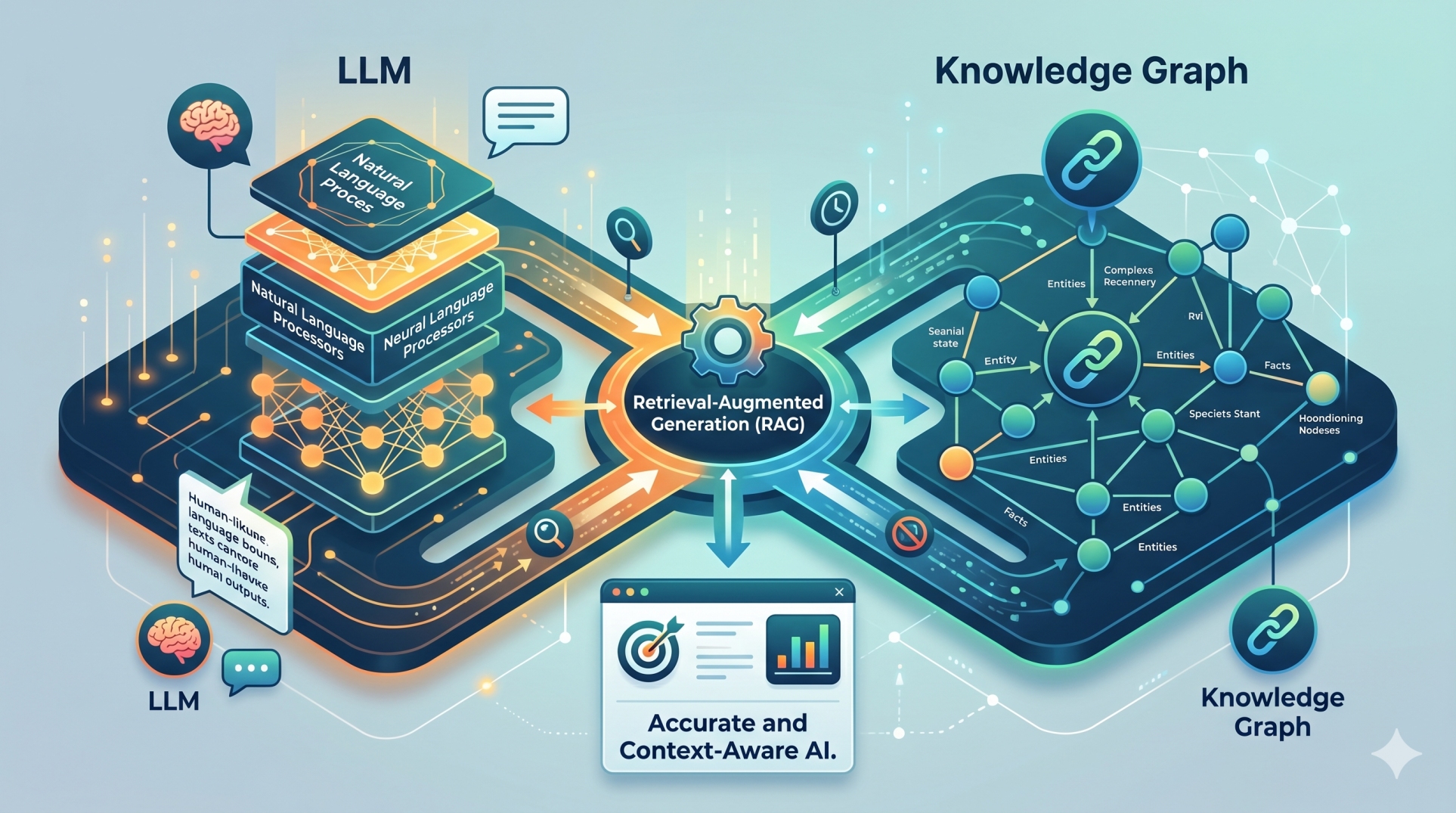
Step 5: Applying Retrieval-Augmented Architectures Efficiently 🔎
• Retrieve precise supporting information instead of expanding prompts 📚
• Constrain generation using grounded context 📌
• Decouple retrieval logic from generation workflows 🔗
• Reduce correction cycles caused by inaccurate outputs 🛠️
• Optimize context size to control token consumption 📉
Step 6: Implementing Tiered and Hybrid Processing 🧭
• Direct simple queries to cost-efficient models 💡
• Escalate complex tasks only when necessary ⬆️
• Use pre-processing rules before invoking LLMs 📜
• Introduce fallback mechanisms for balanced performance ⚖️
• Continuously refine routing logic using usage analytics 📊
Step 7: Enforcing Cost Monitoring and Governance 📊
• Measure token usage by feature and workflow 📈
• Set budget caps and automated alerts 🚨
• Calculate cost per interaction or customer 🧮
• Evaluate return on investment across use cases 💼
• Provide visibility into spending through reporting dashboards 📋
Step 8: Architecting for Long-Term Economic Sustainability 🏗️
• Design systems around business value, not raw model capability 💡
• Focus on cost per meaningful outcome rather than per request 🎯
• Maintain flexible architectures that adapt to pricing or vendor shifts 🔄
• Continuously reassess cost-performance balance as usage scales 📈
Conclusion
Building cost-aware architectures is fundamental to sustaining LLM applications in production environments. Through thoughtful model selection, prompt optimization, intelligent caching, and tiered routing strategies, organizations can maintain strong performance while controlling operational expenditure. When cost efficiency is embedded into architectural design from the outset, LLM-powered systems can grow responsibly and deliver durable business value.
See more blogs
You can all the articles below