How RAG Works: A Simple Guide to Retrieval Augmented Generation

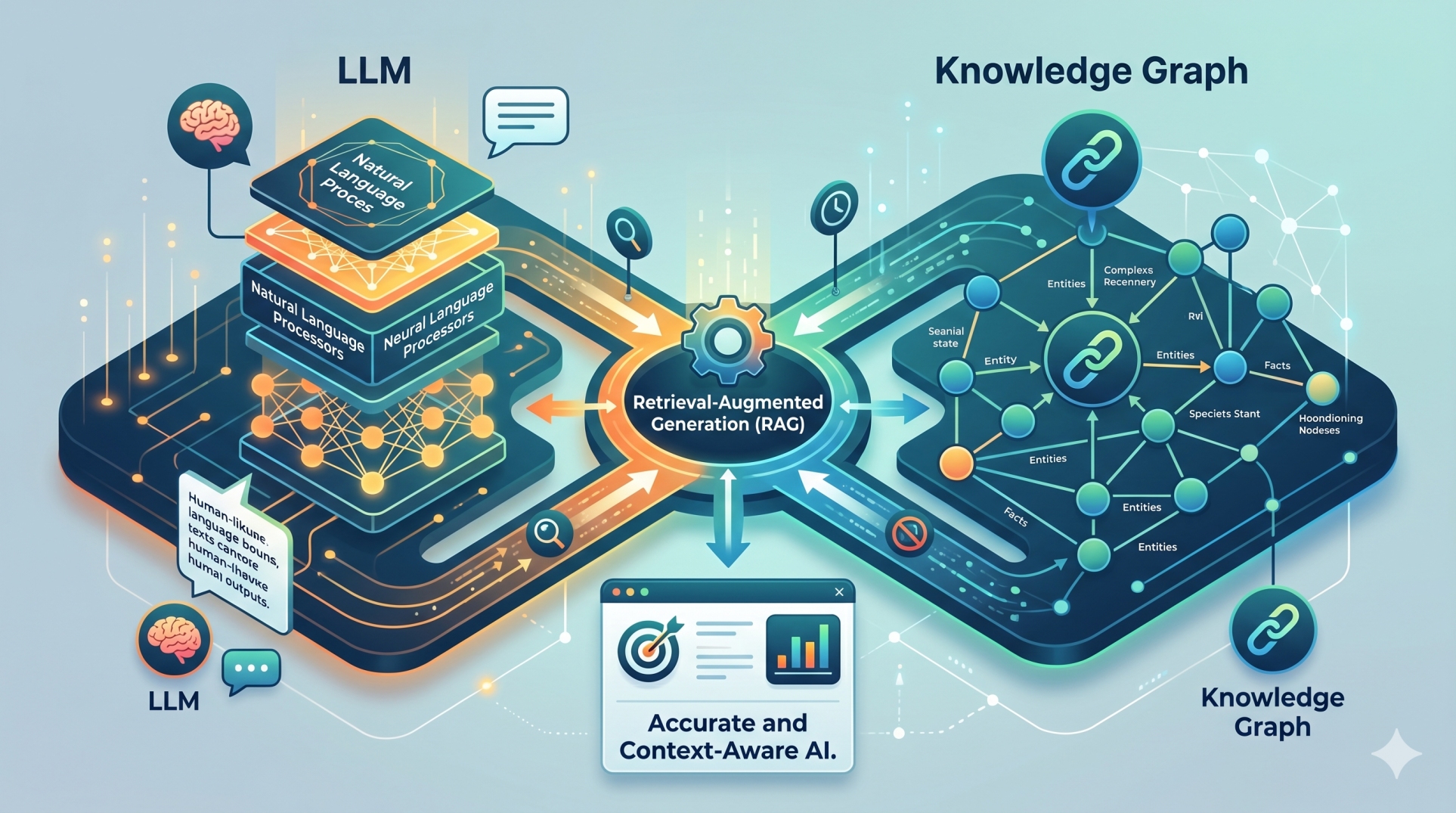
In the evolving world of AI, RAG (Retrieval Augmented Generation) has emerged as a game-changer. It solves a core limitation in traditional language models: the lack of up-to-date or domain-specific information. Let’s break down how RAG works using the visual above and understand why it matters for anyone building AI-driven apps.
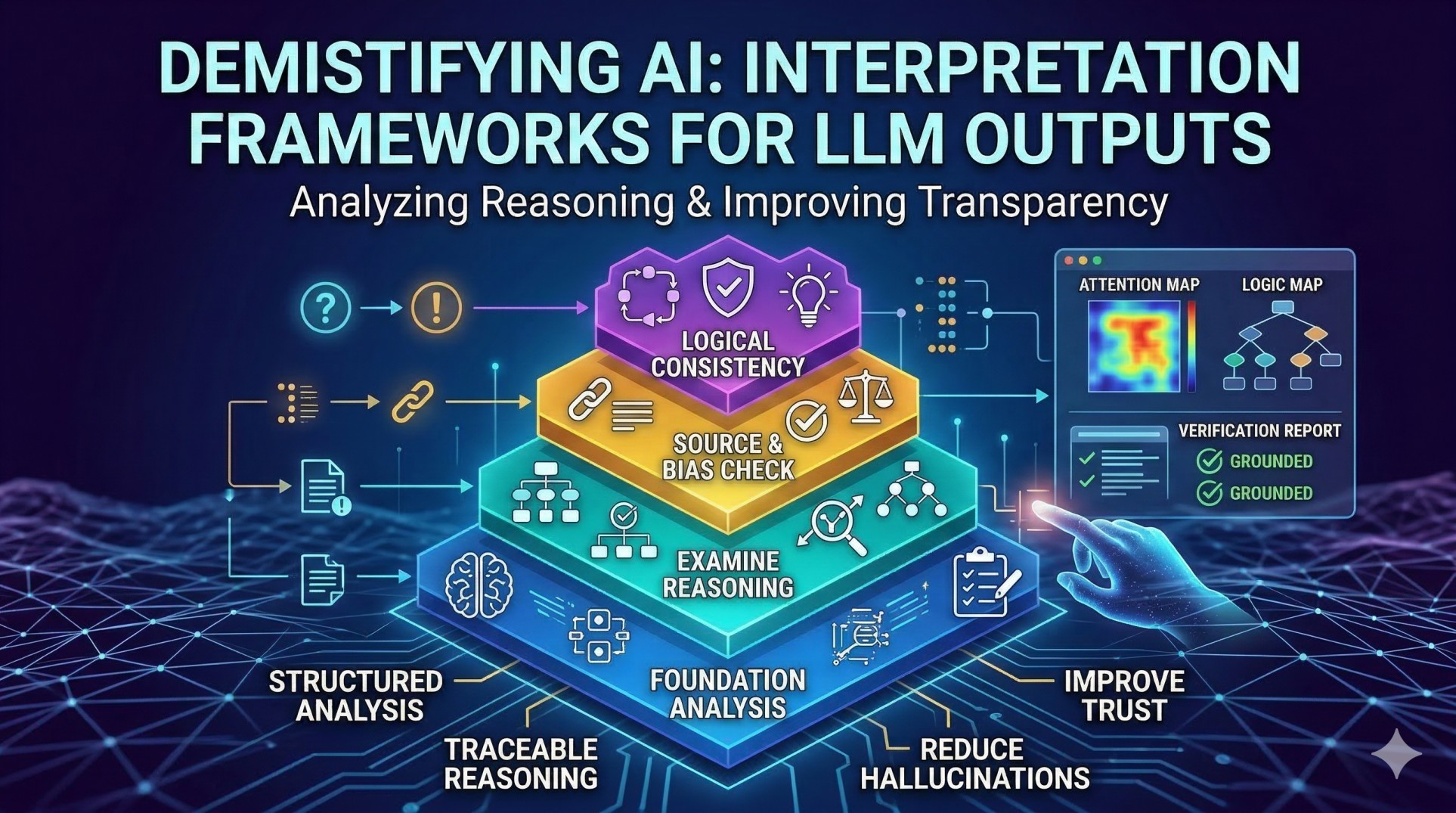
🔍 What Is RAG?
RAG stands for Retrieval Augmented Generation, a framework that combines a retriever (search) and a generator (language model) to produce more accurate, context-aware, and up-to-date answers. Instead of relying only on what the model was trained on, RAG taps into external data sources in real time.
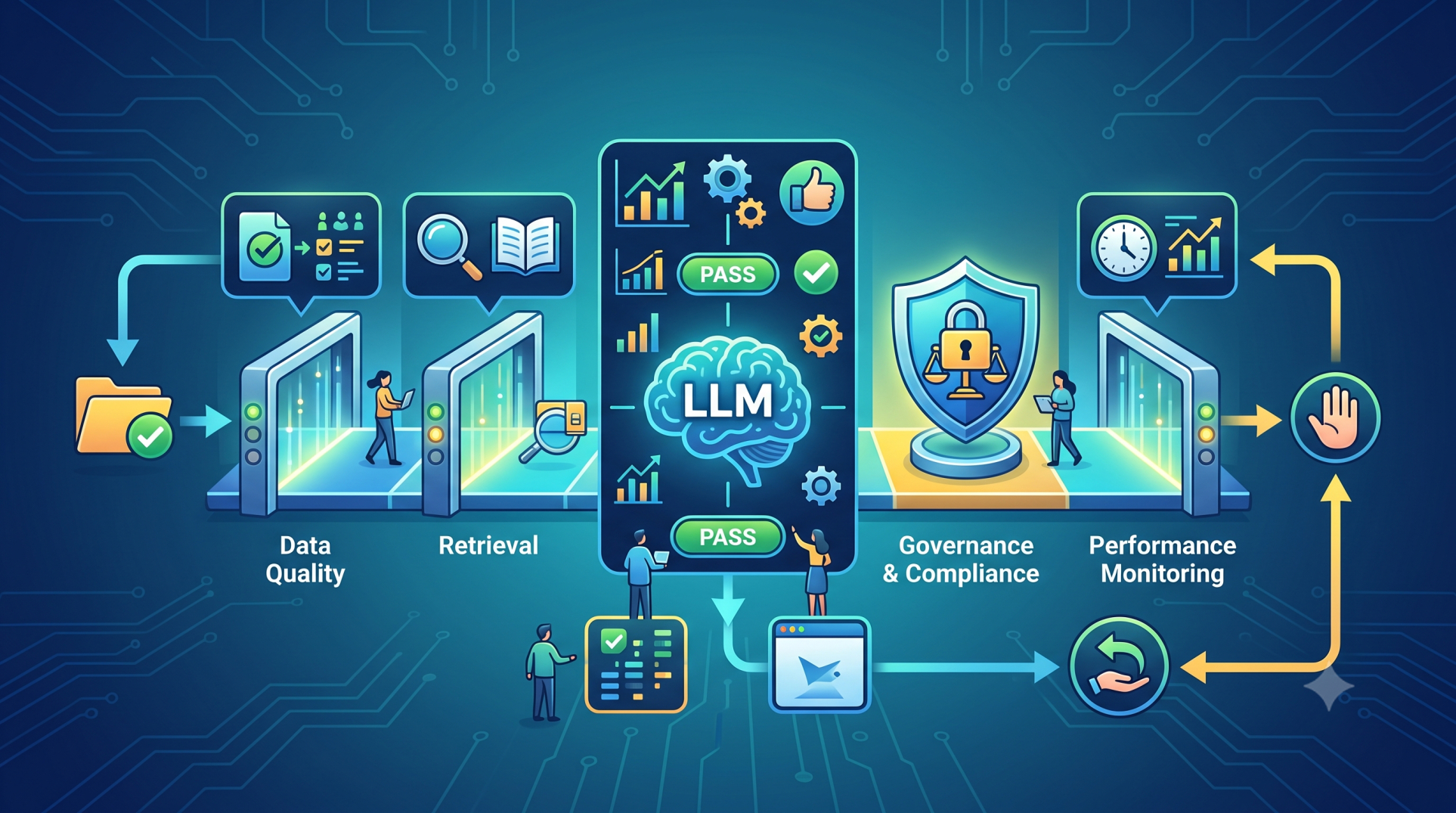
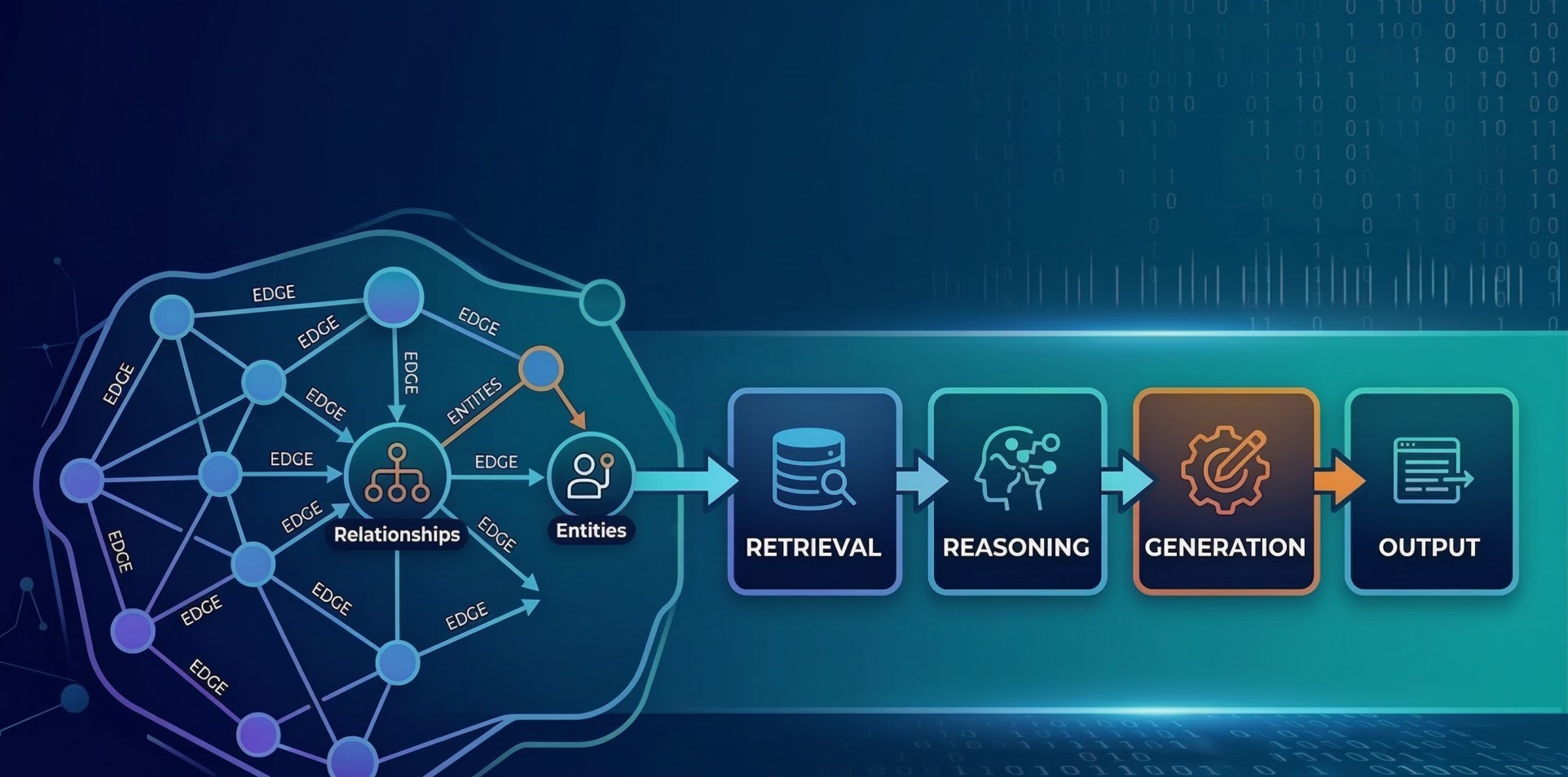
🧠 Step-by-Step: How RAG Works
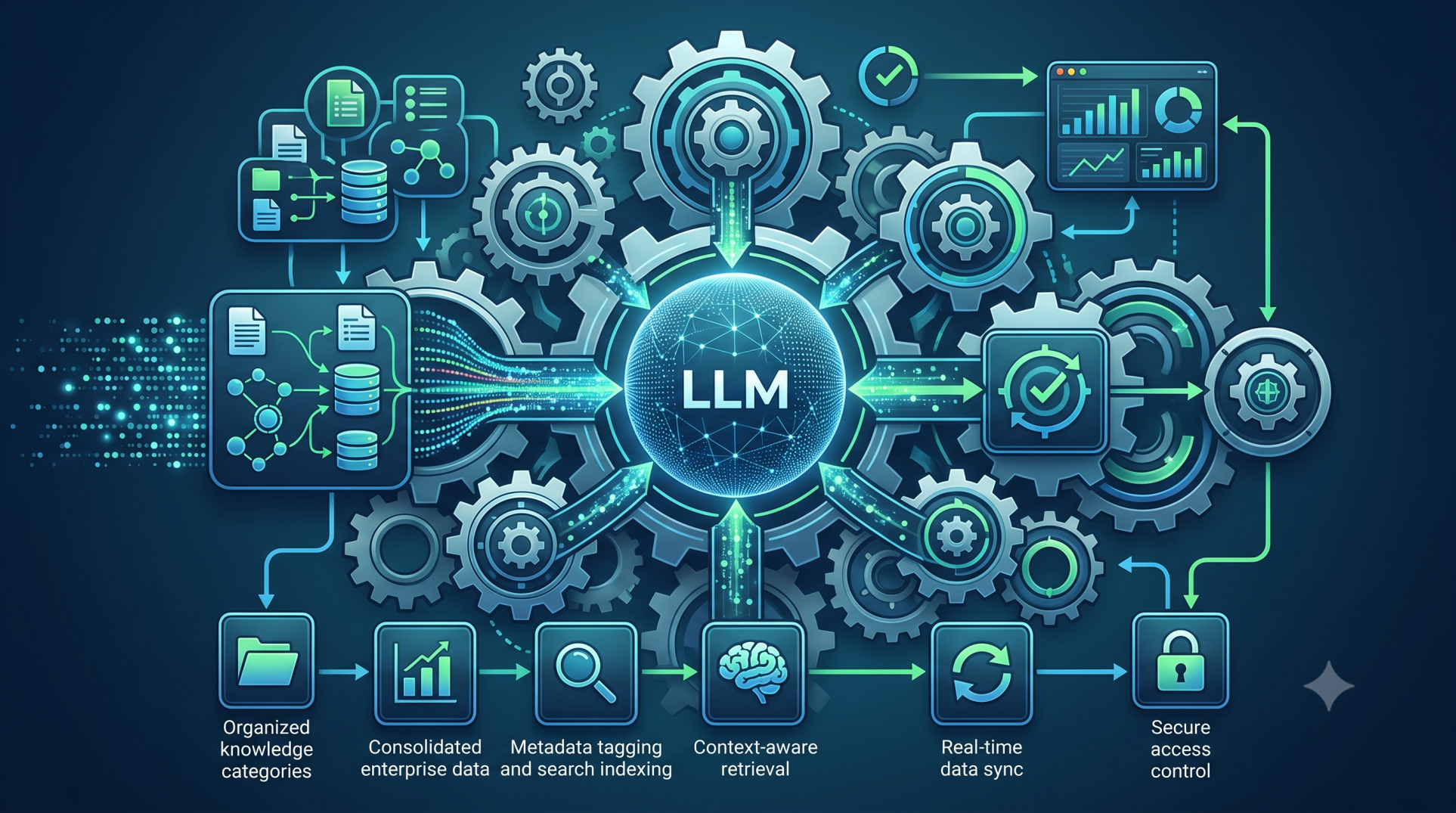
1. Data Preparation
- Start with a database of documents or information.
- Use an embedding model to convert text into vectors (numerical representations).
- These vectors are indexed and stored in a vector database for fast retrieval.
2. Retrieval
- When a user asks a question (text query), it’s converted into a vector embedding.
- A similarity search is performed to retrieve the most relevant chunks of information.
- These retrieved documents (context) are passed along with the query to the language model.
3. Generation
- The language model (LLM) combines the retrieved content and the original prompt.
- This enriched context allows the LLM to generate a more informed and grounded answer.
💡 Without RAG vs With RAG
❌ Without RAG:
A model might respond:
"I am unable to provide comments on future events... I do not have any information regarding the dismissal and rehiring of OpenAI’s CEO."
✅ With RAG:
The response is insightful and grounded:
"This suggests significant internal disagreements within OpenAI regarding the company’s future direction and strategic decisions..."
This is possible because the RAG model pulled relevant, real-time documents into the generation pipeline.
🔄 Real-Life Example from the Visual
User Query:
“How do you evaluate the fact that OpenAI’s CEO, Sam Altman...”
RAG retrieves documents like:
- "Sam Altman Returns to OpenAI as CEO"
- "The Drama Concludes"
- "The Personnel Earthquake"
Final Answer:
An informed and nuanced explanation based on these references, showing how RAG enhances credibility and relevance.
⚙️ Why RAG Matters for LLMSoftware.com
For enterprise applications, customer support, or internal knowledge bots, hallucinations are costly. RAG ensures your models aren’t just generative — they are grounded in your actual data.
With RAG:
- You get answers aligned with your documents, policies, or knowledge base.
- You can update the knowledge base anytime without retraining the model.
- Your responses are explainable and backed by sources.
We have integrated internal and external sources like https://brightdata.com/ to get the update relevant data.
🚀 Build with Confidence
At LLMSoftware.com, we’re making RAG integration effortless — connect your documents, vector store, and LLM, and you’re ready to deploy production-grade AI that truly understands your world.
Want to see how RAG fits into your business? Book a demo and let us show you how Retrieval Augmented Generation can transform your AI workflow.
See more blogs
You can all the articles below