Building Smarter AI with the RAG Developer's Stack

🔍 Building Smarter AI with the RAG Developer's Stack
At LLMSoftware.com, we help companies supercharge their AI capabilities. One of the most transformative architectures powering real-world AI applications today is RAG – Retrieval-Augmented Generation. RAG combines the power of language models (LLMs) with external knowledge sources for more accurate, real-time, and context-aware answers.
If you're building AI tools for customer service, document summarization, or enterprise search, RAG is the gold standard. But how do you actually build with RAG? The answer lies in using the right tools across each layer of the stack.
Here’s a breakdown of the RAG Developer’s Stack curated by Anil Inamdar, covering everything from LLMs to evaluation frameworks.
🧠 LLMs – The Brains Behind the Stack
These are the foundation models powering your generation capabilities:
- OpenAI, Claude, Gemini, Cohere
- Open-source models like LLaMA 3.3, Mistral, DeepSeek, Phi-4, Qwen 2.5, Gemma 3
🧰 Frameworks – Orchestrating the Workflow
These libraries streamline the flow between data retrieval and LLM prompts:
- LangChain
- LlamaIndex
- Haystack
- txtai
- AWS Bedrock
They help manage prompt chains, agents, routing logic, and integrations.
🧱 Vector Databases – Memory for Fast Retrieval
To enable semantic search and retrieval, you need high-performance vector stores:
- Pinecone, Chroma, Qdrant
- Weaviate, Milvus
These databases store document embeddings and return the most relevant chunks at query time.
🕸️ Data Extraction – Feeding the Knowledge Graph
You can't generate insights without relevant data:
- Crawl4AI, FireCrawl, ScrapeGraphAI
- MegaParser, Docling, LlamaParse
- Extract Thinker
These tools crawl, parse, and structure data into usable context for your LLM.
🌐 Open LLM Access – Hosting & Speed
Need fast inference or open-source alternatives?
- Hugging Face, Ollama, Groq, Together AI
These platforms let you run or fine-tune models efficiently, often at lower cost or latency than closed APIs.
🔡 Text Embeddings – Powering the Search Layer
Transform your data into vector form using:
- OpenAI, SBERT, BAAI BGE, Voyage AI, Cohere, Google, Nomic
These embeddings form the basis of accurate semantic retrieval in your RAG pipeline.
✅ Evaluation – Measuring Accuracy & Faithfulness
Once built, evaluate your pipeline with:
- Giskard
- Ragas
- Trulens
These tools assess hallucination rates, relevance scores, latency, and other QA metrics to ensure reliability.
🚀 Why This Stack Matters
At LLMSoftware.com, we help integrate these tools into your AI workflows — whether you're building:
- Smart document search
- AI assistants for internal knowledge
- Legal/medical chatbots
- Or custom vertical RAG tools with multi-modal data
This stack enables modular, flexible, and production-grade AI systems.
🔗 Ready to Build with RAG?
Let’s help you go from prototype to production. Reach out to integrate these tools or see a demo of what a full-stack RAG pipeline looks like in action.
Stay ahead. Build smarter. Build with RAG.
See more blogs
You can all the articles below
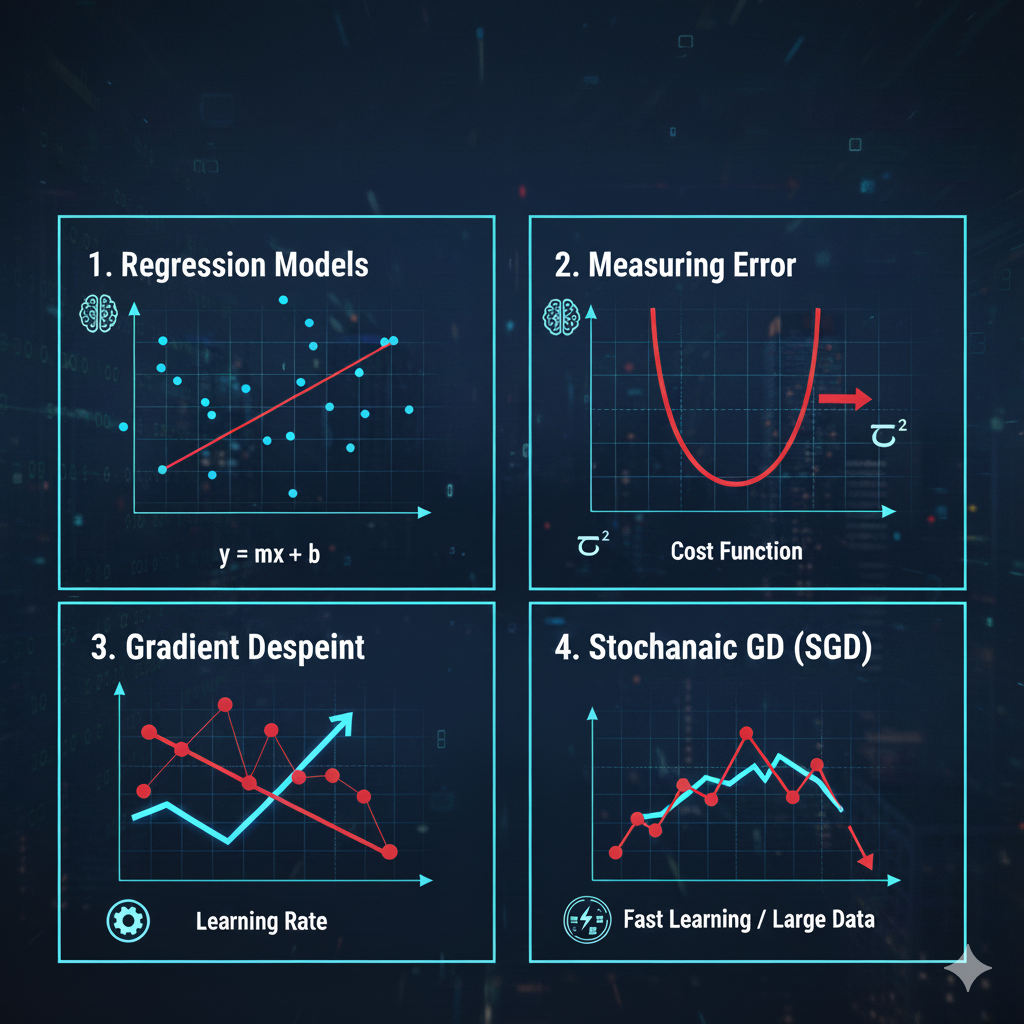




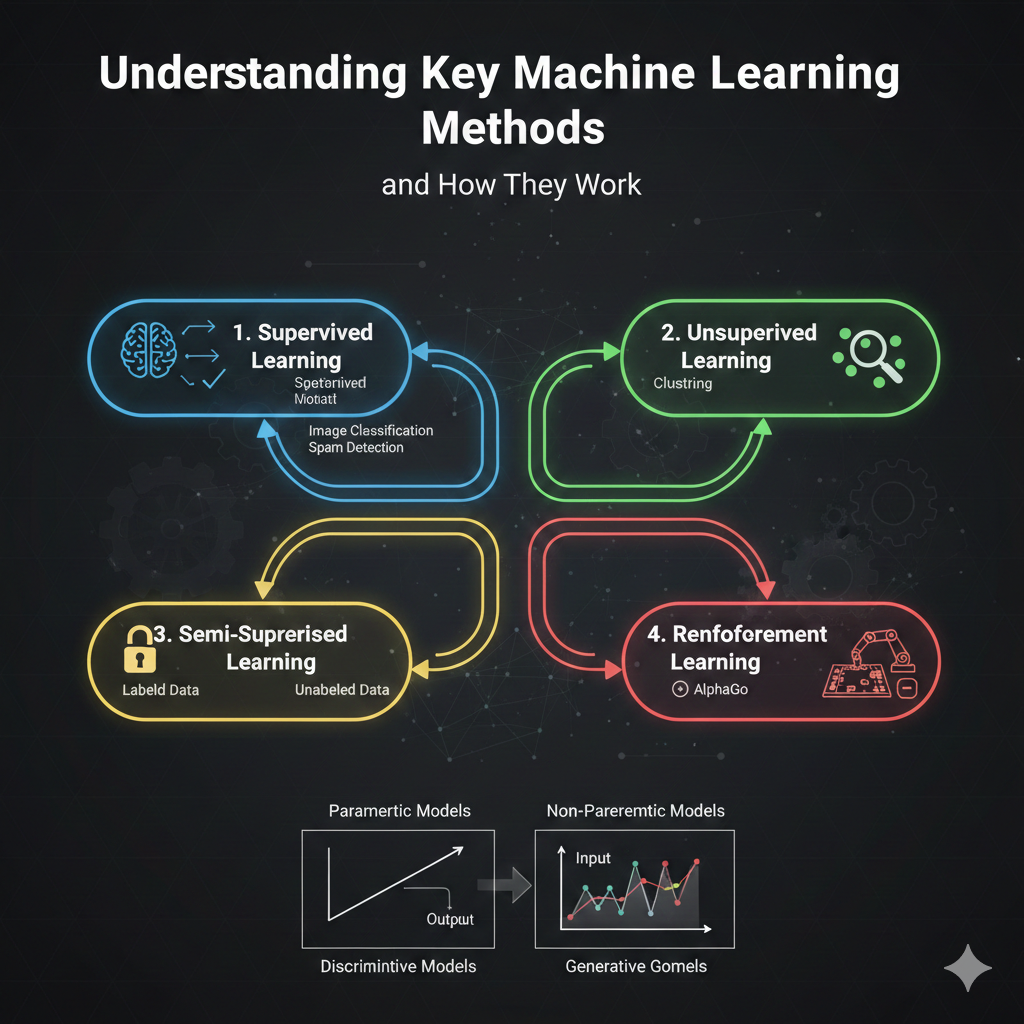


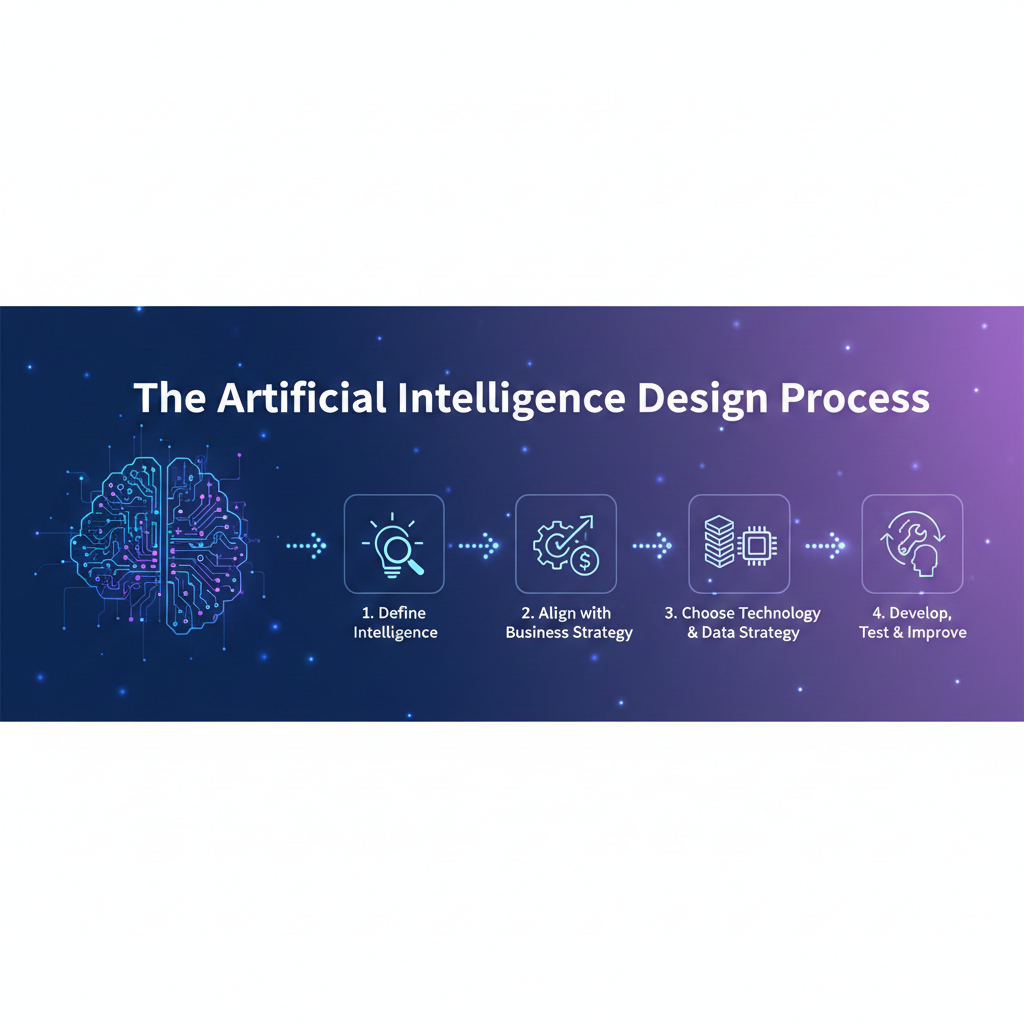
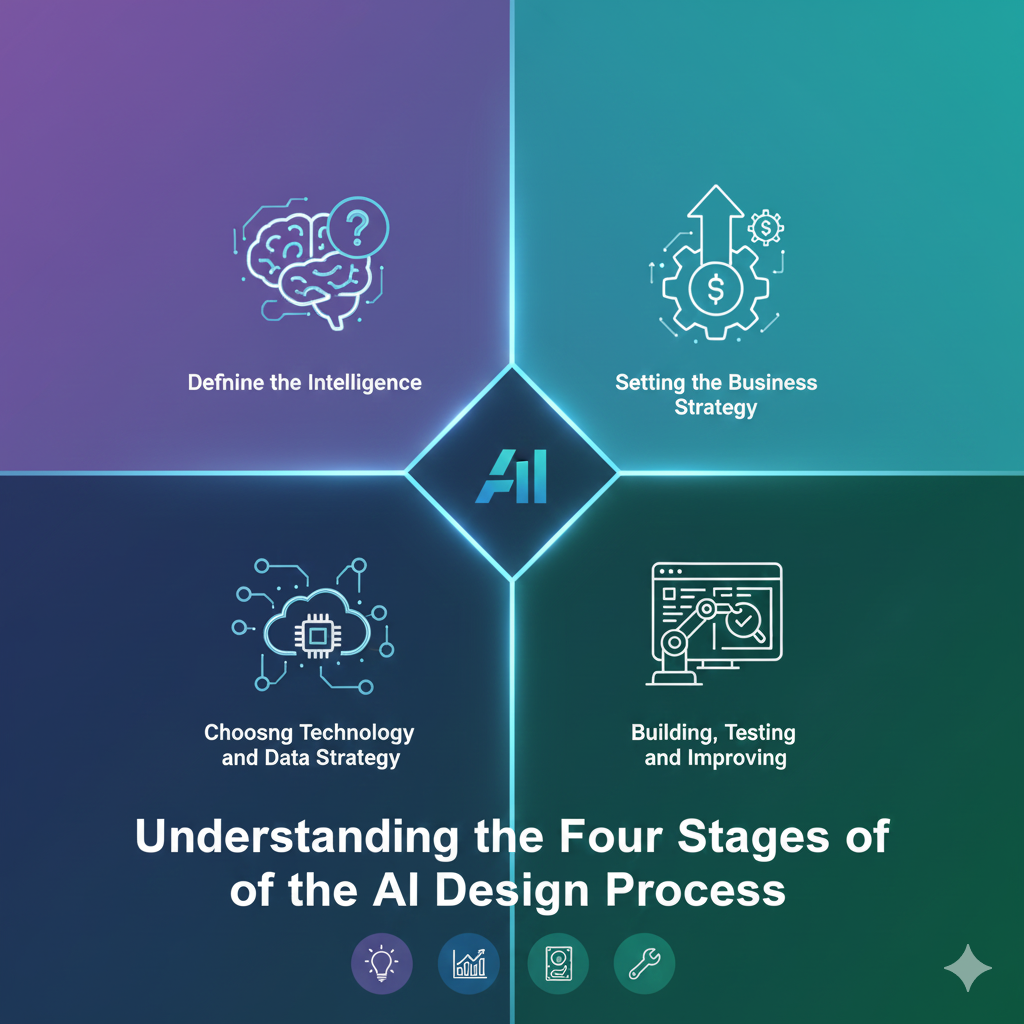





.png)










